
This is the output that Bookends, my bibliography software, produces when I tell it to create a tag cloud based on the 100 most frequently used keywords in my ~1500 entry bibliography. It is a nice visual indication of my research interests. I like it so much that I am thinking if I couldn’t include this little treat in my applications, to attract those with a more visual approach.
Archive for the ‘tech’ Category
Updated to WordPress 3.0.
Monday, June 21st, 2010A few days ago, a major update for WordPress (the software that I use to maintain this blog) has been published: version 3.0 Thelonious
. I just finished the install, without any hiccups. I guess there won’t be many differences for you to notice… the only thing that I noticed is that the new WordPress default theme is not that unlikely to the theme that I came up with for this site (well, it does look more refined, but the basic elements like the header image, right-handed sidebar, and a larger default font are the same. That feels nice.
Migration to WordPress.
Sunday, January 24th, 2010Since I got the job to set up a blog for someone else, and since it was decided that the blog should be done with WordPress, I started to play around with this blogging package a few days ago. To learn how to set things up and make modifications, I tried to replicate the style of my own blog, which is based on the very simple blosxom. One thing came to another and finally I tried to import all of my blosxom blog entries into the new WordPress database – and here we are! I decided to switch to WordPress because:
- it is maintained much more regularly,
- it is much more comfortable to use,
- it offers more and more useful plugins,
- I hope it will make it easier to keep off spam,
- it finally allowed me to make a tag cloud.
The latter can be marvelled at to the right. I am quite baffled at how closely the tag cloud represents those aspects of my life that I put into this blog in the course of the last six years. It will be interesting to see how the cloud develops in the future…
I decided against keeping the content in the same address location because of the cryptic cgi blabla that was part of the old address. Therefore I would like to ask you to update your bookmarks and feed readers to go to the new address: http://userpage.fu-berlin.de/frers/blog.
More privacy for you.
Monday, November 16th, 2009For more than seven years I have used Sitemeter to see and analyze the traffic to my website. The service was originally recommended to me by Jörg Kantel, but in recent years I grew more and more disenchanted by Sitemeter – they teamed up with different advertising partners, made their JavaScript more complex, and there is also the ongoing privacy related discussion. In addition, because it could only count those visits that actually accessed the JavaScript code that is embedded into a HTML page, Sitemeter did not count those who would not activate the script. So the count missed out on those who block JavaScript and it also never counted access to the PDF, audio and video files that I host here.
In spite of all of these disadvantages, there was no real alternative for me, since Google Analytics is even worse when it comes to data collection, and since I did not have access to the webserver logs. All of this changed a few months ago when zedat, FU’s IT unit made it possible to access the weblogs for the userpage that they host. Since that change, I have now and then experimented with this feature, and with the help of the nice staff at zedat, I was able to set up a working solution using cron jobs and Visitors. Although Visitors is somewhat dated and not as feature-rich as I would like, it is good enough to finally get rid of Sitemeter. (And installing/using it does not require a lot of technical skills.)
So beginning today, accessing my website will: 1. better preserve your privacy and 2. be faster, since my pages are now completely JavaScript free and since your browser won’t have to access several different domains to load a single page. Win-win situation for you and me!
Sitemeter’s final count for this site was: 128,247 Visits and 193,571 Page Views.
Upgrading video on website to HTML 5.
Monday, October 5th, 2009In the course of the last month I have recoded all of my pages with video content to conform to the current working draft of HTML 5. The nice thing is that there already is a code validator for HTML 5, so that I found some things that have changed from HTML 4 to 5 that I would have overlooked. (For example the fact that the <acronym> tag isn’t part of the standard anymore and that <abbr> should be used instead.)
The main reason for me to switch to HTML 5 was the new <video> element. Until now, I have used different hacks to embed video into the website without breaking standard conformance or having to use Flash. Or I have used the official standard implementation, which left users of Internet Explorer in the cold anyway. So I was never really content with the way that I offer video because it would either be really hackish code, or it would not validate, or it would break in one or another browser. (Opera for example did not allow some of the officially validating hacks to work…) So now I am using clear and clean HTML 5 code. The only obstacle that I had to overcome was to get Firefox to display the video. I thought this wouldn’t be a problem since Firefox officially supports the video tag beginning with version 3.5. The first code that I wrote looked something like this:
<video controls src="passage.mp4">
<a href="passage.mp4" title="right click to download the file">video file (24 MB)</a>
</video>
This worked perfectly fine in Safari (version 4), but in Firefox I would only get a grey field with an X where the video should be. I did not mind at first, since I was happy to get things running, my code was validating and it was built on an example that I found on the pages of the W3C itself. After a few days, I was bothered by this solution, since about half of the visitors of my website use Firefox and I certainly did not want them to be left in the cold. So I searched a bit and finally found the corresponding bugs on Mozilla’s website (435298 for the Mac and 435339 for Windows) and a general discussion of the issue. In all of these places, the Firefox developers clearly state that they won’t be supporting MPEG codecs and also won’t hook the video element up with the plugin architecture of the respective OSs. Instead, Firefox is implementing the open source Ogg Theora video codec that is not plagued by licensing issues in the way the MPEG-4 codecs are. (There is a pretty thorough discussion about this on Ars Technica.) Well, I never used Ogg stuff for anything so far, but I read that the quality of their video compression improved greatly over the course of the last year. It is open source, which I like, and Mozilla decided to try to push it, so I finally decided to give it a shot. Of course, offering embedded video support to all my visitors using Firefox was a pretty big incentive too… After a lot of experimenting, fiddling around with different encoder settings and comparing encoding results with QuickTime X’s h264 encoded files, it became clear, that the quality of Theora is indeed worse than what h264/mp4 offers, but that it is still certainly good enough for presenting video on my website – only very few people will notice the difference between the two formats (but they will notice that the .ogg files are bigger).
I had to change the code a bit to offer both video formats. I chose to use Ogg Theora as the fallback format because of the better quality (smaller size at same quality) of the h264 encoding. My current implementation looks like this:
<video controls>
<source src="passage.mp4" type="video/mp4">
<source src="passage.ogg" type="video/ogg">
Video file: <a href="passage.mp4" title="right click to download the file">MP4/.264 (24 MB)</a> | <a href="passage.ogg" title="right click to download the file">Ogg Theora (47 MB)</a>
</video>
This way, Firefox 3.5 and Safari 4 show the embedded video with controls, while all other browsers (I tested Camino 1.6, Opera 9 and 10, and Internet Explorer 7 and 8) fall back to displaying the direct links to the video files. After doing some more testing, I must say that I prefer Firefox’s implementation of the video element to Safari’s, because Firefox will only download the video file when it is actually activated by the user, whereas Safari will start the download of all embedded video files immediately, thus clogging my internet connection as soon as I open the website.
If you want to check out how I implemented things, you can visit this page, where I also used HTML 5’s new <audio> element: Pacification by Design.
Much better spelling support in Snow Leopard.
Wednesday, September 2nd, 2009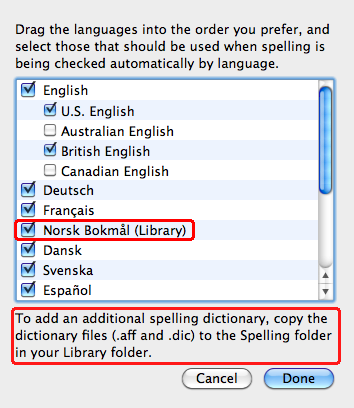 When I wrote an e-mail in Norwegian today, I again had to realize how bad I am with my spelling. Since I just installed Apple’s new operating system Snow Leopard I went to check if it happens to support Norwegian spelling correction. It did not. But when I checked out the new spelling options in the Text tab of System Prefences’ Language & Text panel, I saw the picture that you can see here too. This means that OS X 10.6 supports spelling dictionaries such as those used by OpenOffice. Yay! That means that we now have a ton of other spelling options without having to resort to services like CocoASpell, which never really worked too well for me.
When I wrote an e-mail in Norwegian today, I again had to realize how bad I am with my spelling. Since I just installed Apple’s new operating system Snow Leopard I went to check if it happens to support Norwegian spelling correction. It did not. But when I checked out the new spelling options in the Text tab of System Prefences’ Language & Text panel, I saw the picture that you can see here too. This means that OS X 10.6 supports spelling dictionaries such as those used by OpenOffice. Yay! That means that we now have a ton of other spelling options without having to resort to services like CocoASpell, which never really worked too well for me.
So now getting support for other languages is as easy as visiting an OpenOffice dictionary server to download the dictionary you need, unzipping the dictionary and dropping the .dic and the .aff file into the Spelling folder inside the Library folder. (Either in your home directory, or, if you want to install the dictionary for all users of your machine, into the root level Library’s Spelling folder.) The great thing is that we now have full spelling support for many, many languages in all applications that support Apple’s spelling services, e.g. in TextEdit, Pages, Nisus, Mellel,… What a wonderful day!
Bye bye, Internet Explorer 6.
Sunday, August 2nd, 2009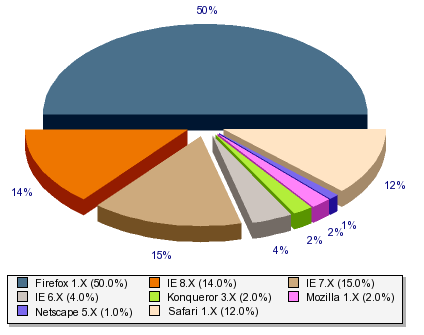 Well, it is more than five years ago that I blogged about the fading away of people using Netscape Navigator 4.x versions to visit my website, a year later about the reduction in people browsing my site with Internet Explorer 5.x and about the first sightings of Internet Explorer 7.
Well, it is more than five years ago that I blogged about the fading away of people using Netscape Navigator 4.x versions to visit my website, a year later about the reduction in people browsing my site with Internet Explorer 5.x and about the first sightings of Internet Explorer 7.
Today things are different, and Microsoft’s Internet Explorer 6.x is the beast that keeps me from implementing cleaner HTML code for this website. But there are good news: In the last months, the number of people visiting this site with Internet Explorer 6.x has more and more often been smaller than the number of users browsing the web with the current 8.x incarnation of the beast. This is good news, because the new version 8.x is much more standards compliant and it finally, finally supports the use of the quote tag <q>. That means that more people will acutally see the quotation marks around the quotes (“” for English, „“ for German) that I coded into this blog and the other pages offered here.
When the amount of IE 6.x users consistently remains below three percent, I will kick out the hacks that I put into the code to work around IE 6.x’s annoyances. Maybe that will also be the day when I will introduce the first pages that are coded in HTML 5, something that I am really looking forward to because the new <video> element will make embedding video in a standards conformant way much easier.
Faster, bigger, better.
Monday, November 17th, 2008Last week, I finally took the financial and technical plunge and exchanged my MacBook Pro’s internal 160 GB drive with a new 320 GB drive taken from a LaCie rugged hard disk case. The exchange was not as easy as it was with my trusty old Pismo Powerbook, but it also was much less of a hassle than exchanging the hard disk of my first generation Blueberry iBook. Using the excellent tutorials offered on iFixIt, replacing the drive is about a 15-30 minute procedure.
My main worry was if it would be possible to extract the hard disk from the LaCie rugged disk shell or if the nice rubber frame would be glued to the case, thus making it necessary to damage the case. However, you can just pull the very flexible rubber bumpers and then extract the metal shell. You don’t even need any special tools for exchanging the drive in the rugged disk frame. (You need a # 7 torx and a # 00 phillips for the MacBook Pro, though.)
Everything went fine except for the fact that I accidentally unplugged a tiny plug on the logic board when I took off the keyboard. Because of this, the MacBook Pro would not start at all after I exchanged the hard disk and screwed things back. It did not even make the famous gong sound anymore. What got me really worried was that the Magsafe power plug that goes into the laptop did not show the regular red or green light dot. Instead it blinked – very rapidly and very faintly! Uh oh. That did not look good at all. I disassembled the case once more, did not find anything wrong and reassembled it again. Still no startup, still only the worrying LED blinking. Well, I took the thing apart once more, now doing what all technicians do when machines fail for unknown reasons: unplug and replug every single plug that you can reach. In this case, I only reached the fourth plug when I noticed that is wasn’t firmly plugged in. Pushing it back into its socket. Screwing screws back into their sockets. Sacrifice a chicken. Turn around clockwise three times and counterclockwise seven times. Push the power button. Yay! Everything is working as it should be. Yours truly truly happy.
The hard disk that was in the 320 GB rugged disk enclosure is a 5400 rpm Hitachi HTS543232L9A300 – exactly the same model as was in there before, only with 320 instead of 160 GB. Since that means that more (i.e. the double amount) data is put on the same surface, the disk is quite a bit faster than the old one. This is especially noticeable during startups. Very nice!
Putting the data from the old drive on to the new drive was a bit more complicated than I thought, because I used the LaCie tool to format the new disk. The LaCie drive tool formats the disk with the old Apple Partition Table instead of the new GUID Partition Table. Since intel Macs can only boot from GUID partitioned drives, I had to reformat the disk and check the appropriate option in Apple’s Disk Utility before I could use the new drive to boot my MacBook Pro. After choosing the correct partitioning technique, I first wanted to use Carbon Copy Cloner to clone the contents of my old drive to the new one. But the clone was not bootable because of some strange permission issues. Again, going back to the tools provided by Apple made things work: I used Apple’s Disk Utility once more and told it to restore
the contents of my old internal drive to the new external drive. This went perfectly well. (I bought one of the triple interface rugged disk models and used the faster FireWire 800 to transfer the data. USB is well-known to suck with regards to data transfer rates…)
I also used this opportunity to expand my Boot Camp partition for Windows XP to double the former size. Thanks to the excellent tool Winclone this was quite easy. I first booted up Window XP and converted the disk from FAT32 to NTFS using the standard windows command. Then I booted back into Mac OS X and cloned the Boot Camp partition to a disk image using Winclone. Then I put in the new disk and used Apple’s Boot Camp Assistant to make a Windows partition twice the size of the old one. In the next step, I used Winclone to clone the contents of the disk image onto the new, larger Boot Camp partition. Finally I used the Expand Windows (NTFS) Filesystem…
command offered by Winclone to expand the partition to use the new, bigger size it offers. This worked perfectly well and this gives me enough room on my windows partition to install the new expansion pack for LOTRO when it arrives this week. Ha!
Some blog functions currently broken.
Tuesday, November 11th, 2008Dear readers, please bear with me! The university that hosts this blog, Freie Universität Berlin, is currently shifting web services to a new server system. One of the neat side effets of this change is that now we can use PHP and MySQL goodies for the websites hosted by zedat, the university’s IT department. One of the bad side effects is that some things may be broken temporally. In the case of this blog, the archive, permanent links, and everything that does not appear on this front page is broken. My guess is that the new cgi script service does things differently when scripts want to generate dynamic web pages… I am confident that this problem will be resolved soon: the zedat team offers the best university IT service that I have had the pleasure to deal with. Stay tuned.
Say hello to my 100000th visitor.
Wednesday, August 20th, 2008 Woot! After being online for more than six years, my website got the onehundredthousandth visitor. It’s been a while and quite a few things have happened during this time. A blog was added, the layout changed a bit here and there (mostly on the main home page) and quite a bit of video and text content was uploaded. Some of the changes to the website can be tracked in the Internet Archive’s WayBackMachine.
Woot! After being online for more than six years, my website got the onehundredthousandth visitor. It’s been a while and quite a few things have happened during this time. A blog was added, the layout changed a bit here and there (mostly on the main home page) and quite a bit of video and text content was uploaded. Some of the changes to the website can be tracked in the Internet Archive’s WayBackMachine.
Schöne Suche.
Wednesday, April 30th, 2008Heute hat jemand nach wer hat den Ozean erfunden gegoogelt und ist in diesem Blog gelandet. Sehr hübsch. Ich weiß nicht, ob ich es bedauern soll, die Antwort nicht zu wissen…
Getting the research back to the name of this blog.
Friday, March 16th, 2007 Finally. I am currently spending my first research week on the island. My main objective during this stay is to arrange future stays, check out the general way things have changed in the course of the last 10+ years, get back into touch with people, and take a lot of photographs of the island’s coastline, nature, buildings, places, and people. Some of the photos serve more or less aesthetic purposes, documenting the attractions and peculiarities of this place, others serve as a background for future assessments or comparisons.
Finally. I am currently spending my first research week on the island. My main objective during this stay is to arrange future stays, check out the general way things have changed in the course of the last 10+ years, get back into touch with people, and take a lot of photographs of the island’s coastline, nature, buildings, places, and people. Some of the photos serve more or less aesthetic purposes, documenting the attractions and peculiarities of this place, others serve as a background for future assessments or comparisons.
Time passes both more slowly and more quickly here. To keep a grip on this and the many other things and thoughts that I encounter here, I have started writing a more thorough log than I did for any of my past research projects. I am pretty sure solid logging practices (as recommended by Lofland & Lofland in their great book Analyzing Social Settings) are a very good idea for a long-term project such as mine. I can only recommend OmniOutliner to those of you using a Mac. It is as useful for keeping a log as it is for writing outlines.
Small tip for those who have to check their spam folders.
Tuesday, February 27th, 2007Since no spam filter is perfect and nothing is worse than ham classified as spam, I have to check the contents of the different spam folders of my e-mail accounts somewhat regularly. For some of them, several hundred spam mails per week are not a rare occurrence – thus it can be a real drag to check all of their titles for possible ham (that is e-mails that are good and actually addressed to me, not unsolicited ads, phishing stuff, and all the other stupid things). Last week I tried something new to help my perception: I ordered the contents of the spam folders by subject! Incredible, isn’t it? That makes picking out potential ham much easier, especially in those cases where you have lots of spam messages with almost identical subject lines. Probably you have already figured this out on your own, but maybe not – and then you owe me one ;)
Digital Photography.
Friday, November 3rd, 2006I am really content with my new camera, a Canon EOS 400D. The image quality is most excellent, the amount of noise even at the maximum ISO value (1600) is quite small, it reacts almost instantaneously, and it offers a whole lot of interesting, useful, and even easily accessible settings. Photography has become even more fun!
Before buying this camera, I used my old Canon EOS 300 to make slides. After four to eigth months I would take all my new slides and scan them in a several day session using a high-resolution slide scanner (a Nikon 4000). Even with all the time and work that I invested during these scanning marathons, the image quality of the pictures taken by the 400D is just plain better, especially regarding noise. And that is not even considering the numerous usability advantages of digital cameras. The best thing is that I can still use the lens that I bought for my 300: a pretty good Canon EF 28-105 II USM. Not losing this investment is what finally convinced me of buying the 400D. The only disadvantage is that the 400D crops images at a 1.6 ratio. That means that all my pictures are effectively taken at a longer focal range – 28-105mm becomes 44.8-168mm. Because of this, it has become difficult to shoot interiors… I guess that means I will need to get a wide angle lens eventually.
 The picture you see here is showing the limits even of this new camera: I wanted to shoot Oslo at night from the plane with which I arrived here the evening before yesterday. I particularly liked the scene because of the moonlight reflecting on the waters of the Oslofjord. However, planes are moving fast and even with ISO 1600 the camera needed a one second exposure time. Thus the result shown here.
The picture you see here is showing the limits even of this new camera: I wanted to shoot Oslo at night from the plane with which I arrived here the evening before yesterday. I particularly liked the scene because of the moonlight reflecting on the waters of the Oslofjord. However, planes are moving fast and even with ISO 1600 the camera needed a one second exposure time. Thus the result shown here.
The space of a dissertation.
Sunday, September 10th, 2006 Since I am writing about the production of space right now, and since I neglect abstract or representational space in my dissertation a bit, I want to offer at least to you, dear readers, a small insight into the space in which I myself produce knowledge and abstractions. On the image here you can see what my workspace looks like. (You can click on it to open or download it at full size.) Actually, I still enjoy this environment and I am very thankful to the Redlers for producing such an excellent piece of software. Not a single crash, and that with more than 140 images.
Since I am writing about the production of space right now, and since I neglect abstract or representational space in my dissertation a bit, I want to offer at least to you, dear readers, a small insight into the space in which I myself produce knowledge and abstractions. On the image here you can see what my workspace looks like. (You can click on it to open or download it at full size.) Actually, I still enjoy this environment and I am very thankful to the Redlers for producing such an excellent piece of software. Not a single crash, and that with more than 140 images.
Einbalsamierung mal anders.
Wednesday, July 5th, 2006Es ist geschafft. Anlässlich des Auslaufens unseres Graduiertenkollegs haben Reinhard und ich die Webseiten des Kollegs überarbeitet und in einen Zustand überführt, in dem sie den Zustand des Kollegs an seinem Ende für die Nachwelt erhalten – sie wurde gleisam mit standardkonformem XHTML 1.0 Code einbalsamiert. Mumien im Internet. Eine politisch korrekte Mumie, denn sie genügt auch noch recht vielen Kriterien der Barrierefreiheit. Das Antlitz dieser Mumie soll also nicht abschreckend, sondern eher eine Fundgrube für weitere Untersuchungen sein – es sind keine Labors oder Computertomografien notwendig, um sich das Innenleben der Mumie zu erschließen. Ein paar Klicks genügen.
Leaving Boston and re-enabling comments.
Sunday, March 1st, 2009Well, well, the stay in Boston has been very nice – new friends and old friends together created a very rich social life. And I even got an article finished! (More about that in another post sometime in the future.)
I had disabled the comment function after a massive spam attack and forgot to turn it on again afterwards. Now comments should be working again!
Tags: Boston, comment, spam, travel
Posted in tech | 1 Comment »