7 Multiple lineare Regression
7.1 Folien
7.2 Daten der heutigen Sitzung

7.3 Code und Ausgaben aus der Vorlesung
Laden der relevanten Pakete
library(report) # Einfaches Erstellen von statistischen Berichten
library(marginaleffects) # Vorhersagen aus Regressionsmodellen
library(modelsummary) # Darstellung von Regressionsmodellen
library(parameters) # Darstellung von Regressionsmodellen
Attaching package: 'parameters'The following object is masked from 'package:modelsummary':
supported_modelslibrary(performance) # Prüfen der Voraussetzungen
library(tidyverse) # Datenmanagement und Visualisierung: https://www.tidyverse.org/── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.2.0 ✔ readr 2.1.6
✔ forcats 1.0.1 ✔ stringr 1.6.0
✔ ggplot2 4.0.2 ✔ tibble 3.3.1
✔ lubridate 1.9.4 ✔ tidyr 1.3.2
✔ purrr 1.2.1 ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errorsLesen und Aufbereiten des Datensatz von Van Erkel & Van Aelst
d <- haven::read_stata(here::here("data/Vanerkel_Vanaelst_2021.dta")) |>
rename(
Political_knowledge = PK,
Personalized_news = personalized_news,
Radio = News_channels_w4_1,
Television = News_channels_w4_2,
Newspapers = News_channels_w4_3,
Online_news_sites = News_channels_w4_4,
Twitter = News_channels_w4_5,
Facebook = News_channels_w4_6
) |>
mutate(
Gender = as_factor(Gender),
Education = as_factor(Education),
trad = factor(trad, labels = c(
"traditional news diet: no",
"traditional news diet: yes"
))
)Einfaches Modell mit zwei Prädiktoren
simple_model <- lm(Political_knowledge ~ Age + Newspapers, data = d) |>
report_table(metrics = "R2_adj")
simple_modelParameter | Coefficient | 95% CI | t(990) | p | Std. Coef.
-----------------------------------------------------------------------
(Intercept) | 0.99 | [0.67, 1.31] | 6.07 | < .001 | 4.02e-16
Age | 0.02 | [0.02, 0.03] | 8.24 | < .001 | 0.24
Newspapers | 0.22 | [0.18, 0.27] | 9.31 | < .001 | 0.28
| | | | |
R2 (adj.) | | | | |
Parameter | Std. Coef. 95% CI | Fit
--------------------------------------
(Intercept) | [-0.06, 0.06] |
Age | [ 0.19, 0.30] |
Newspapers | [ 0.22, 0.33] |
| |
R2 (adj.) | | 0.16simple_modelParameter | Coefficient | 95% CI | t(990) | p | Std. Coef.
-----------------------------------------------------------------------
(Intercept) | 0.99 | [0.67, 1.31] | 6.07 | < .001 | 4.02e-16
Age | 0.02 | [0.02, 0.03] | 8.24 | < .001 | 0.24
Newspapers | 0.22 | [0.18, 0.27] | 9.31 | < .001 | 0.28
| | | | |
R2 (adj.) | | | | |
Parameter | Std. Coef. 95% CI | Fit
--------------------------------------
(Intercept) | [-0.06, 0.06] |
Age | [ 0.19, 0.30] |
Newspapers | [ 0.22, 0.33] |
| |
R2 (adj.) | | 0.16Regression mit binärem Prädiktor Gender
lm(Political_knowledge ~ Gender, data = d) |>
report_table(include_effectsize = FALSE, metrics = "R2")Parameter | Coefficient | 95% CI | t(991) | p | Fit
-----------------------------------------------------------------------
(Intercept) | 3.44 | [ 3.33, 3.55] | 60.48 | < .001 |
Gender [female] | -0.84 | [-1.00, -0.67] | -10.14 | < .001 |
| | | | |
R2 | | | | | 0.09Kontraste des Faktors Bildung: Niedrige Bildung als Referenz (Default)
contrasts(d$Education) |>
as.data.frame() |>
rownames_to_column("Zugehörigkeit") Zugehörigkeit Middle High
1 Lower 0 0
2 Middle 1 0
3 High 0 1Mittelwerte Politisches Wissen nach Bildung
d |>
summarise(
M = mean(Political_knowledge),
.by = Education
) |>
arrange(Education) |>
spread(Education, M)# A tibble: 1 × 3
Lower Middle High
<dbl> <dbl> <dbl>
1 2.58 2.97 3.25Regression Politisches Wissen nach Bildung mit niedriger Bildung als Referenz
lm(Political_knowledge ~ Education, data = d) |>
report_table(include_effectsize = FALSE, metrics = "R2_adj")Parameter | Coefficient | 95% CI | t(990) | p | Fit
------------------------------------------------------------------------
(Intercept) | 2.58 | [2.35, 2.81] | 22.39 | < .001 |
Education [Middle] | 0.39 | [0.13, 0.65] | 2.92 | 0.004 |
Education [High] | 0.67 | [0.41, 0.93] | 5.09 | < .001 |
| | | | |
R2 (adj.) | | | | | 0.03Kontraste des Faktors Bildung: Mittlere Bildung als Referenz
relevel(d$Education, "Middle") |>
contrasts() |>
as.data.frame() |>
rownames_to_column("Zugehörigkeit") Zugehörigkeit Lower High
1 Middle 0 0
2 Lower 1 0
3 High 0 1Regression Politisches Wissen nach Bildung mit mittlerer Bildung als Referenz
d$Education <- relevel(d$Education, "Middle")
lm(Political_knowledge ~ Education, data = d) |>
report_table(include_effectsize = FALSE, metrics = "R2_adj")Parameter | Coefficient | 95% CI | t(990) | p | Fit
-------------------------------------------------------------------------
(Intercept) | 2.97 | [ 2.84, 3.10] | 44.41 | < .001 |
Education [Lower] | -0.39 | [-0.65, -0.13] | -2.92 | 0.004 |
Education [High] | 0.28 | [ 0.10, 0.46] | 3.03 | 0.002 |
| | | | |
R2 (adj.) | | | | | 0.03d$Education <- relevel(d$Education, "Lower")Post-Hoc-Vergleich
lm(Political_knowledge ~ Education, data = d) |>
avg_comparisons(
variables = list(Education = "pairwise")
)
Contrast Estimate Std. Error z Pr(>|z|) S 2.5 % 97.5 %
High - Lower 0.669 0.131 5.09 < 0.001 21.4 0.4109 0.926
High - Middle 0.279 0.092 3.03 0.00241 8.7 0.0988 0.459
Middle - Lower 0.389 0.133 2.92 0.00348 8.2 0.1282 0.651
Term: Education
Type: responsePost-Hoc-Vergleich mit Anpassung der p-Werte und Konfidenzintervalle
lm(Political_knowledge ~ Education, data = d) |>
avg_comparisons(
variables = list(Education = "pairwise")
) |>
hypotheses(multcomp = "bonferroni")
Estimate Std. Error z Pr(>|z|) S 2.5 % 97.5 %
0.669 0.131 5.09 < 0.001 19.8 0.3619 0.975
0.279 0.092 3.03 0.00724 7.1 0.0645 0.494
0.389 0.133 2.92 0.01045 6.6 0.0785 0.700
Term: EducationModelle 1 und 4 schätzen
m1 <- lm(Political_knowledge ~ Radio + Television + Newspapers + Online_news_sites + Twitter +
Facebook + Gender + Age + Education + Political_interest, data = d)
m4 <- lm(Political_knowledge ~ Radio + Television + Newspapers + Online_news_sites + Twitter +
Facebook + Gender + Age + Education + Political_interest + Information_overload, data = d)Modelle 1 und 4 wie im Artikel darstellen
modelsummary(list("Model 1" = m1, "Model 4" = m4),
estimate = "{estimate} ({std.error}){stars}",
statistic = NULL,
gof_map = c("nobs", "adj.r.squared"),
fmt = fmt_decimal(digits = 2, pdigits = 3)
)| Model 1 | Model 4 | |
|---|---|---|
| (Intercept) | 0.46 (0.22)* | 0.67 (0.23)** |
| Radio | -0.01 (0.02) | -0.01 (0.02) |
| Television | 0.08 (0.03)** | 0.09 (0.03)** |
| Newspapers | 0.08 (0.02)*** | 0.08 (0.02)*** |
| Online_news_sites | 0.06 (0.02)** | 0.06 (0.02)** |
| -0.06 (0.04) | -0.05 (0.04) | |
| -0.07 (0.02)*** | -0.07 (0.02)*** | |
| Genderfemale | -0.48 (0.07)*** | -0.46 (0.07)*** |
| Age | 0.02 (0.00)*** | 0.02 (0.00)*** |
| EducationMiddle | 0.28 (0.11)* | 0.27 (0.11)* |
| EducationHigh | 0.48 (0.11)*** | 0.48 (0.11)*** |
| Political_interest | 0.18 (0.01)*** | 0.17 (0.01)*** |
| Information_overload | -0.03 (0.01)** | |
| Num.Obs. | 993 | 993 |
| R2 Adj. | 0.371 | 0.376 |
Ausführliche Regressionstabelle zu Modell 4
m4 |>
report_table(metrics = "R2_adj")Parameter | Coefficient | 95% CI | t(980) | p
---------------------------------------------------------------------
(Intercept) | 0.67 | [ 0.21, 1.12] | 2.90 | 0.004
Radio | -7.45e-03 | [-0.05, 0.04] | -0.34 | 0.736
Television | 0.09 | [ 0.03, 0.15] | 2.80 | 0.005
Newspapers | 0.08 | [ 0.04, 0.13] | 3.46 | < .001
Online news sites | 0.06 | [ 0.02, 0.11] | 2.73 | 0.006
Twitter | -0.05 | [-0.13, 0.02] | -1.37 | 0.171
Facebook | -0.07 | [-0.11, -0.03] | -3.38 | < .001
Gender [female] | -0.46 | [-0.60, -0.32] | -6.34 | < .001
Age | 0.02 | [ 0.01, 0.02] | 6.03 | < .001
Education [Middle] | 0.27 | [ 0.06, 0.48] | 2.48 | 0.013
Education [High] | 0.48 | [ 0.26, 0.69] | 4.27 | < .001
Political interest | 0.17 | [ 0.14, 0.20] | 11.79 | < .001
Information overload | -0.03 | [-0.05, -0.01] | -3.03 | 0.003
| | | |
R2 (adj.) | | | |
Parameter | Std. Coef. | Std. Coef. 95% CI | Fit
------------------------------------------------------------
(Intercept) | -0.08 | [-0.22, 0.06] |
Radio | -9.45e-03 | [-0.06, 0.05] |
Television | 0.08 | [ 0.03, 0.14] |
Newspapers | 0.10 | [ 0.04, 0.16] |
Online news sites | 0.08 | [ 0.02, 0.14] |
Twitter | -0.04 | [-0.09, 0.02] |
Facebook | -0.10 | [-0.16, -0.04] |
Gender [female] | -0.34 | [-0.44, -0.23] |
Age | 0.17 | [ 0.12, 0.23] |
Education [Middle] | 0.20 | [ 0.04, 0.35] |
Education [High] | 0.35 | [ 0.19, 0.51] |
Political interest | 0.34 | [ 0.28, 0.39] |
Information overload | -0.08 | [-0.13, -0.03] |
| | |
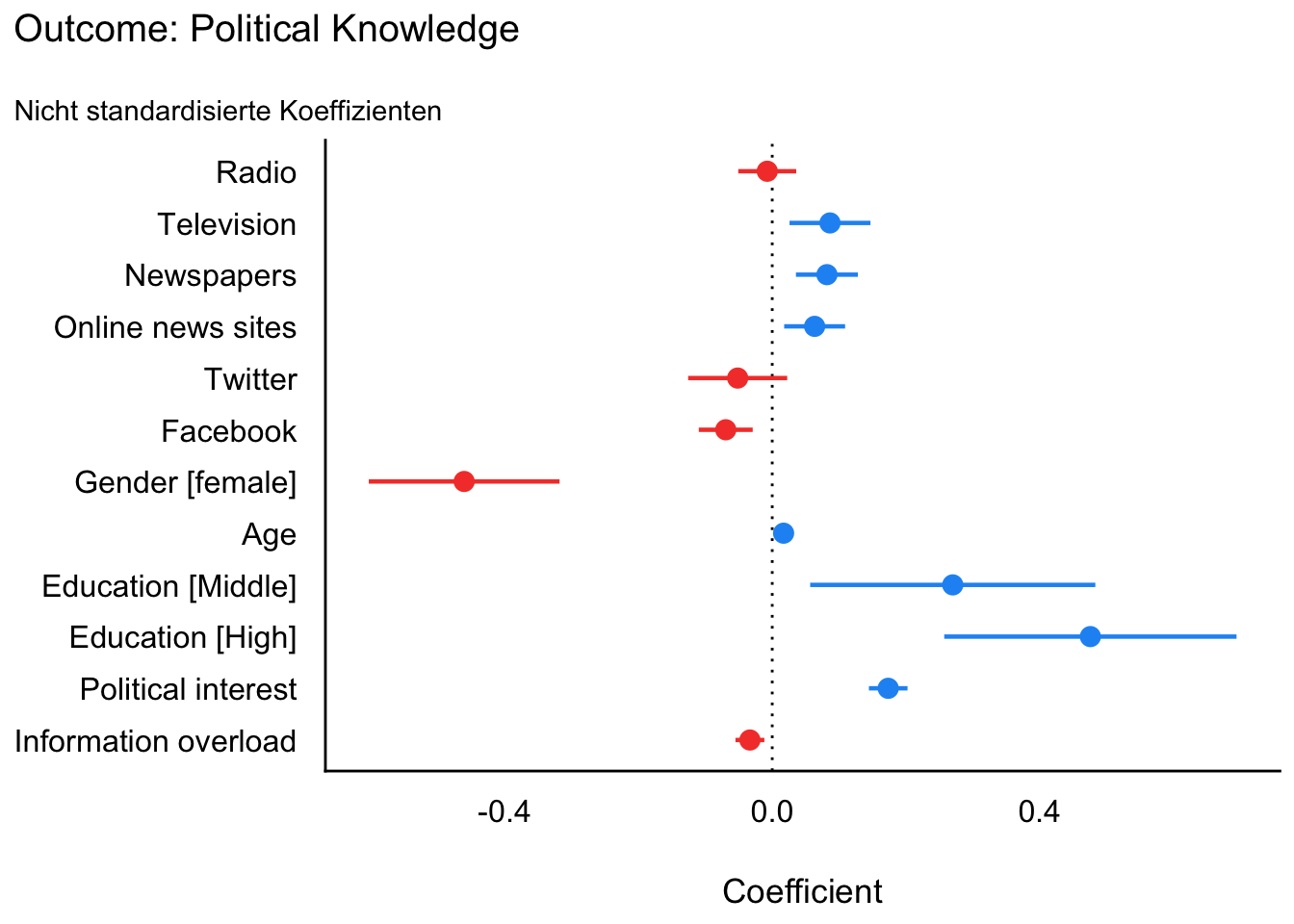
R2 (adj.) | | | 0.38Koeffizientenplot mit nicht standardisierten Koeffizienten
m4 |>
parameters() |>
plot() +
ggtitle("Outcome: Political Knowledge",
subtitle = "Nicht standardisierte Koeffizienten"
)
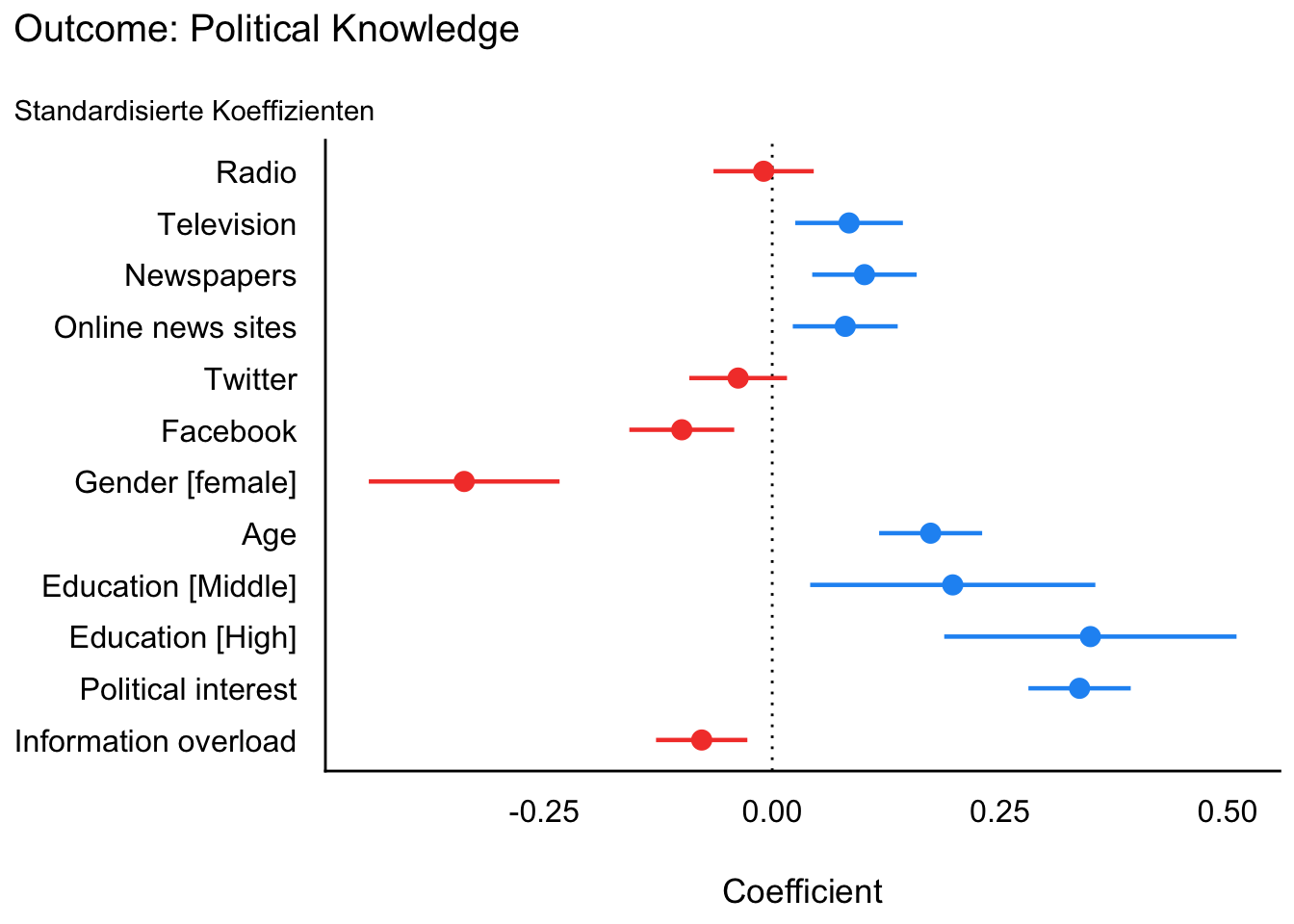
Koeffizientenplot mit standardisierten Koeffizienten
m4 |>
parameters(standardize = "refit") |>
plot() +
ggtitle("Outcome: Political Knowledge",
subtitle = "Standardisierte Koeffizienten"
)
Vorhersage fuer einzelne Praediktoren Plot
theme_set(theme_classic(base_size = 12)) # Layout für Plot
m4 |>
plot_predictions(
by = "Facebook",
newdata = datagrid(
Facebook = 1:6,
grid_type = "mean_or_mode", # Werte der anderen Prädiktoren
FUN_integer = mean
)
) # Notwendig, da sonst für Integer Prädiktoren (keine Nachkommastellen) der Modus ausgewählt wird.
Vorhersage für einzelne Praediktoren Tabelle
m4 |>
predictions(newdata = datagrid(
Facebook = 1:6,
grid_type = "mean_or_mode", # Werte der anderen Prädiktoren
FUN_integer = mean
)) # Notwendig, da sonst für Integer Prädiktoren (keine Nachkommastellen) der Modus ausgewählt wird.
Facebook Estimate Std. Error z Pr(>|z|) S 2.5 % 97.5 %
1 3.53 0.0687 51.4 <0.001 Inf 3.40 3.66
2 3.46 0.0640 54.1 <0.001 Inf 3.34 3.59
3 3.39 0.0657 51.6 <0.001 Inf 3.26 3.52
4 3.32 0.0734 45.2 <0.001 Inf 3.18 3.47
5 3.25 0.0855 38.1 <0.001 1050.3 3.08 3.42
6 3.18 0.1003 31.7 <0.001 731.9 2.99 3.38
Type: responsetheme_set(theme_classic(base_size = 12)) # Layout für Plot
m4 |>
avg_comparisons(variables = list(
Facebook = "2sd", Newspapers = "2sd",
Gender = "reference",
Education = "pairwise"
))
Term Contrast Estimate Std. Error z Pr(>|z|) S 2.5 %
Education High - Lower 0.476 0.1114 4.27 < 0.001 15.7 0.2575
Education High - Middle 0.206 0.0757 2.72 0.00654 7.3 0.0575
Education Middle - Lower 0.270 0.1086 2.48 0.01297 6.3 0.0570
Facebook (x + sd) - (x - sd) -0.270 0.0799 -3.38 < 0.001 10.5 -0.4271
Gender female - male -0.461 0.0727 -6.34 < 0.001 32.0 -0.6030
Newspapers (x + sd) - (x - sd) 0.276 0.0796 3.46 < 0.001 10.9 0.1198
97.5 %
0.694
0.354
0.483
-0.114
-0.318
0.432
Type: responseUeberpruefung von Linearitaet Normalverteilung Homoskedastizitaet Ausreisser Multikollinearitaet einem Befehl
check_model(m4, check = c("linearity", "normality", "homogeneity", "outliers", "vif"))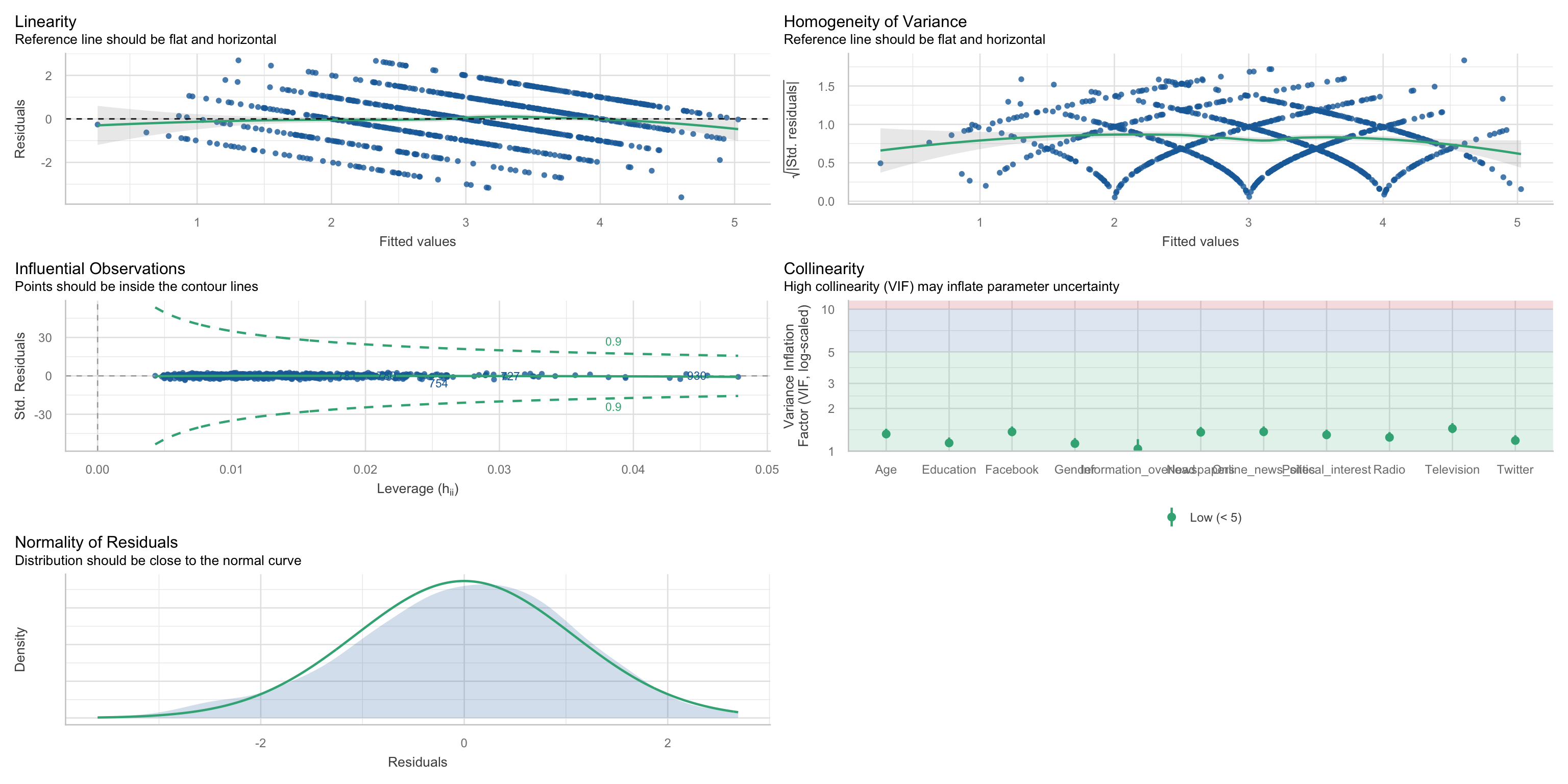
Ueberpruefung Linearitaet
check_model(m4, check = "linearity", panel = FALSE) |> plot()$NCV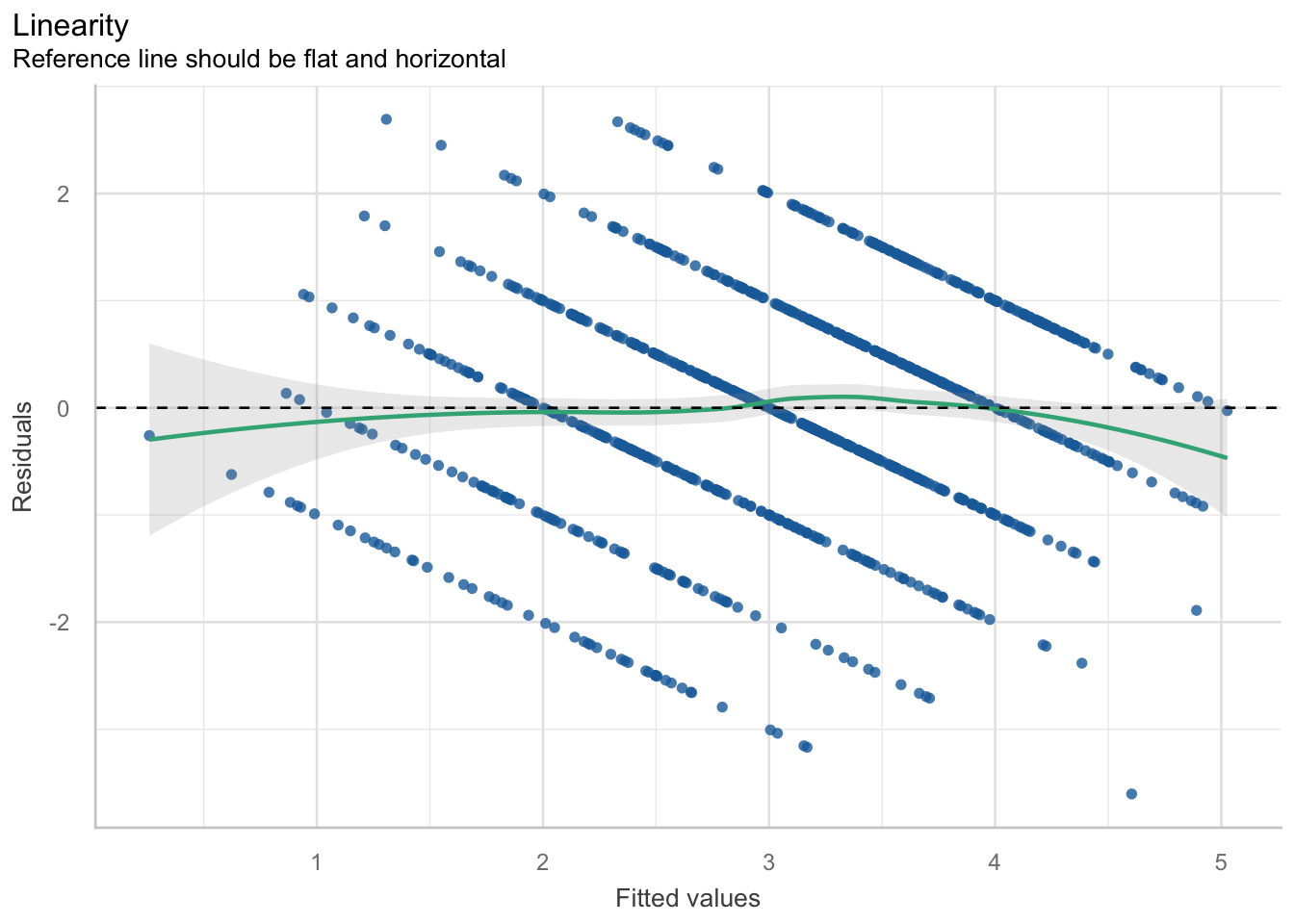
Ueberpruefung Normalverteilung Homoskedastizitaet
check_model(m4, check = c("normality", "homogeneity"))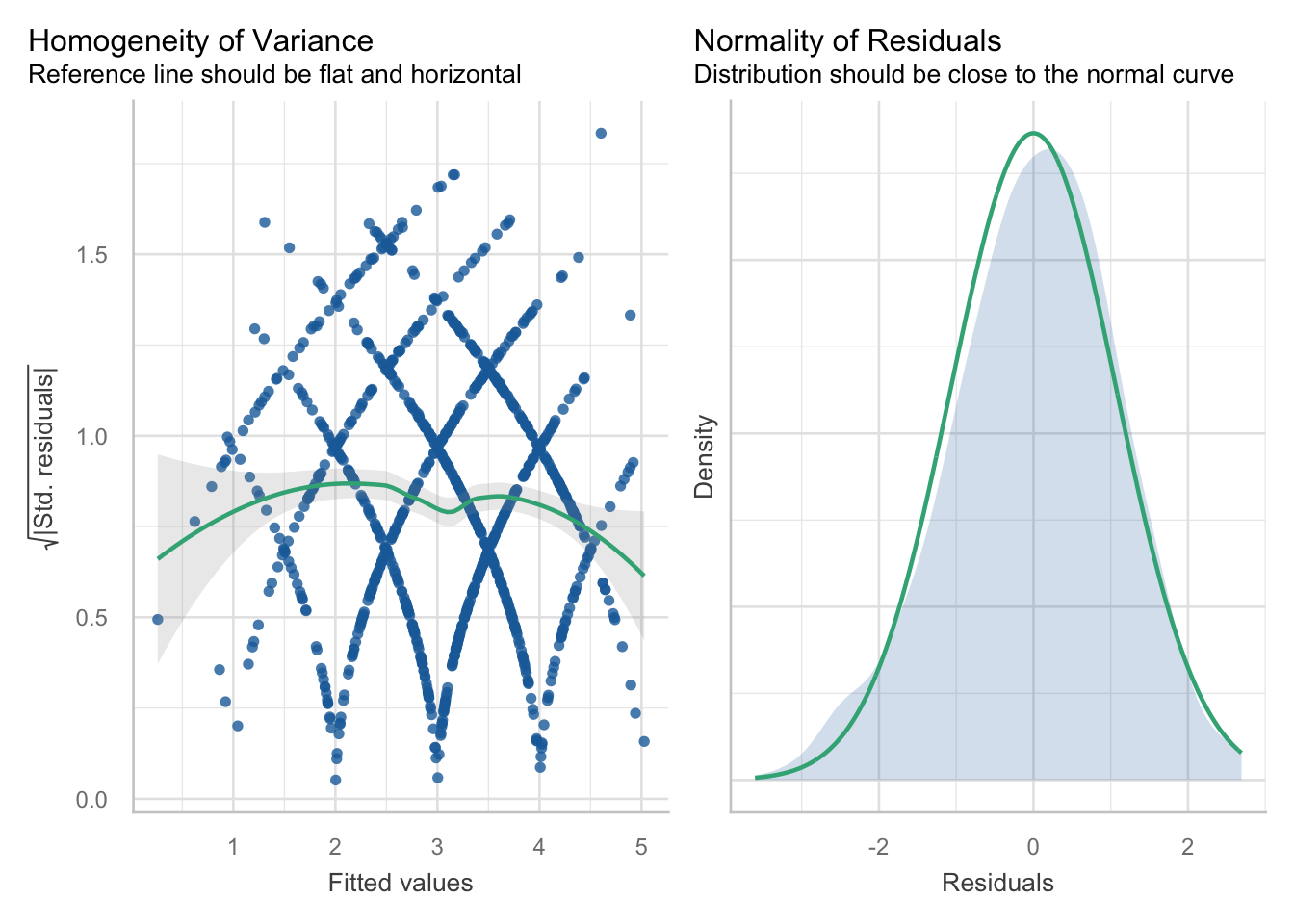
Ueberpruefung Unabhaengigkeit der Residuen
check_residuals(m4) |> plot()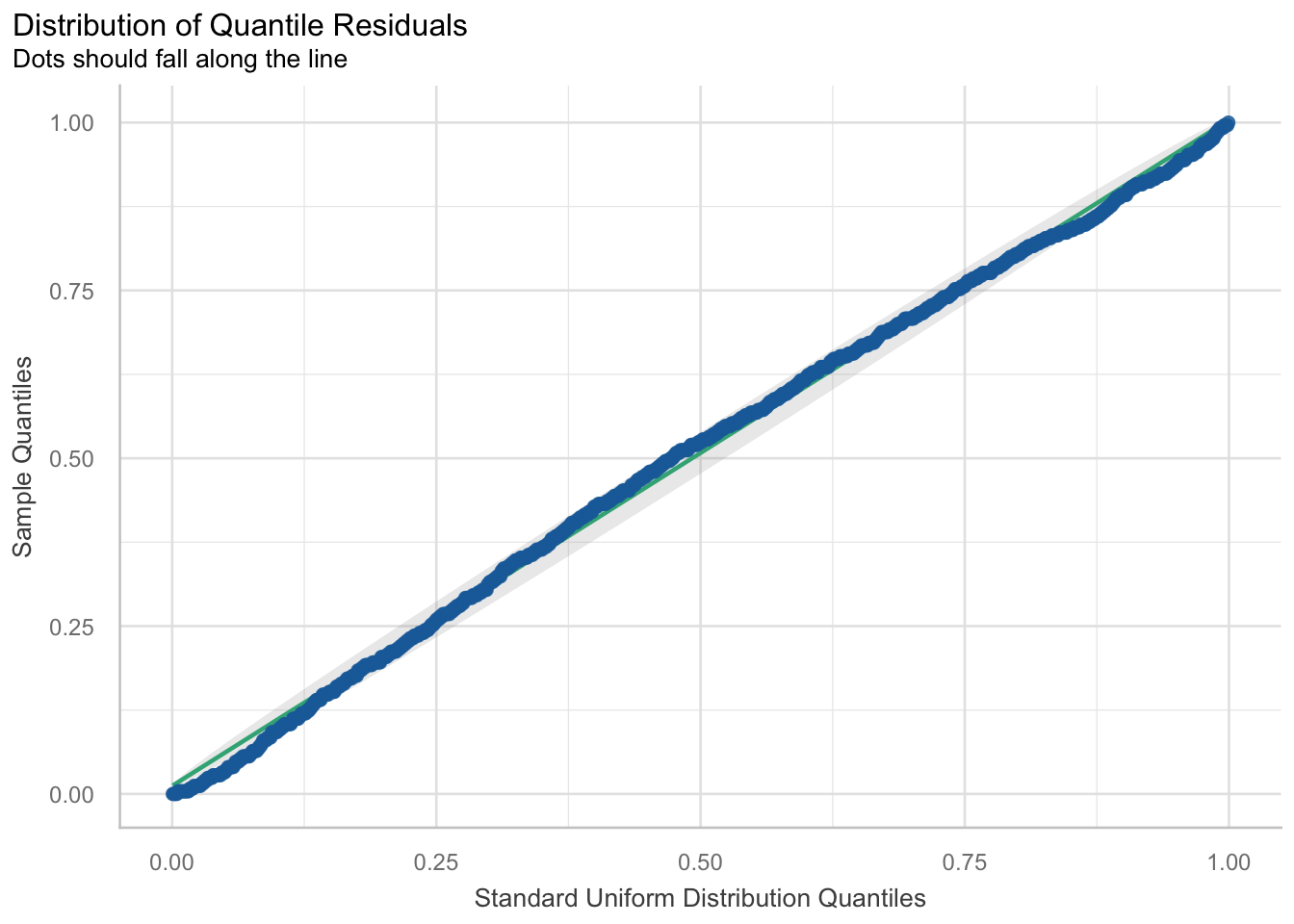
Ueberpruefung Ausreisser
check_outliers(m4) |> plot()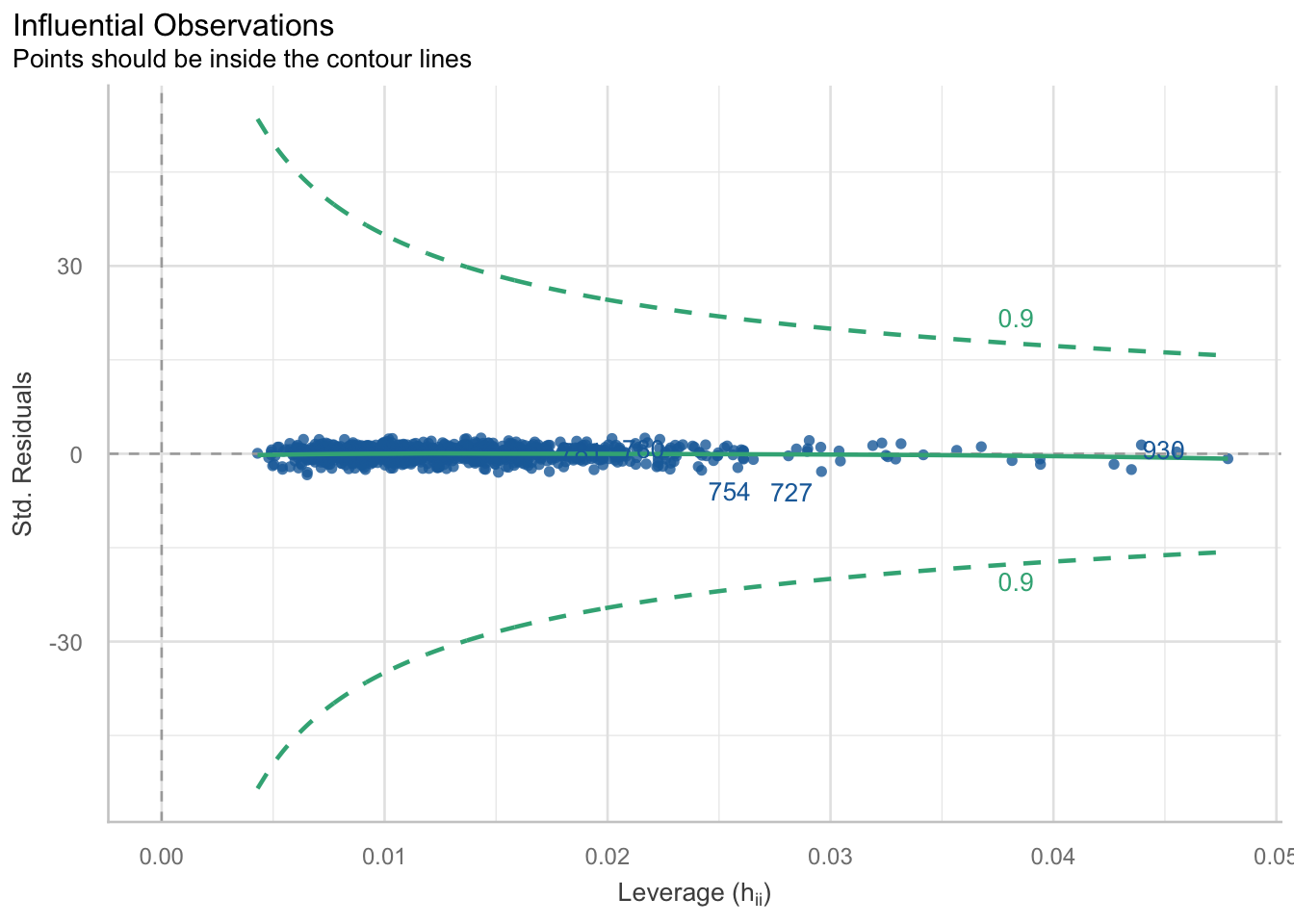
Ueberpruefung Korrelation der Praediktoren
correlation::correlation(m4$model) |> summary(redundant = TRUE)# Correlation Matrix (pearson-method)
Parameter | Political_knowledge | Radio | Television | Newspapers
------------------------------------------------------------------------------
Political_knowledge | | 0.14*** | 0.26*** | 0.33***
Radio | 0.14*** | | 0.39*** | 0.28***
Television | 0.26*** | 0.39*** | | 0.31***
Newspapers | 0.33*** | 0.28*** | 0.31*** |
Online_news_sites | 0.22*** | 0.22*** | 0.28*** | 0.33***
Twitter | -0.04 | 0.09 | 0.04 | 0.09
Facebook | -0.13*** | 0.18*** | 0.19*** | 0.06
Age | 0.30*** | 0.05 | 0.24*** | 0.21***
Political_interest | 0.49*** | 0.20*** | 0.30*** | 0.33***
Information_overload | -0.09* | 0.05 | 0.08 | 0.02
Parameter | Online_news_sites | Twitter | Facebook | Age
-------------------------------------------------------------------------
Political_knowledge | 0.22*** | -0.04 | -0.13*** | 0.30***
Radio | 0.22*** | 0.09 | 0.18*** | 0.05
Television | 0.28*** | 0.04 | 0.19*** | 0.24***
Newspapers | 0.33*** | 0.09 | 0.06 | 0.21***
Online_news_sites | | 0.23*** | 0.27*** | -0.08
Twitter | 0.23*** | | 0.33*** | -0.15***
Facebook | 0.27*** | 0.33*** | | -0.25***
Age | -0.08 | -0.15*** | -0.25*** |
Political_interest | 0.32*** | 0.05 | 0.06 | 0.14***
Information_overload | 0.04 | 0.09 | 0.12** | 0.05
Parameter | Political_interest | Information_overload
----------------------------------------------------------------
Political_knowledge | 0.49*** | -0.09*
Radio | 0.20*** | 0.05
Television | 0.30*** | 0.08
Newspapers | 0.33*** | 0.02
Online_news_sites | 0.32*** | 0.04
Twitter | 0.05 | 0.09
Facebook | 0.06 | 0.12**
Age | 0.14*** | 0.05
Political_interest | | -0.02
Information_overload | -0.02 |
p-value adjustment method: Holm (1979)Ueberpruefung Multikollinearitaet
check_model(m4, check = "vif", panel = FALSE) |> plot()$VIF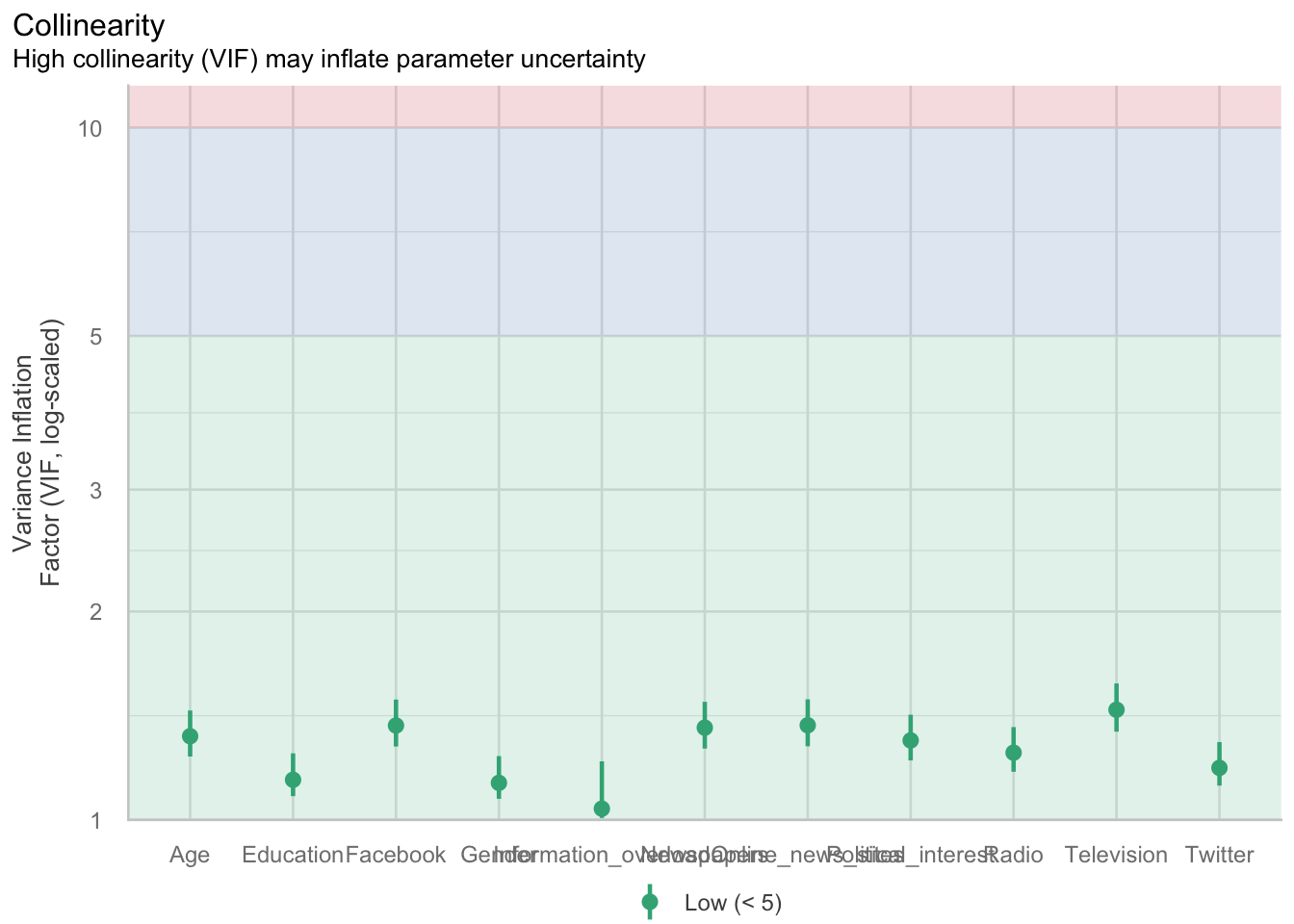
7.4 Hausaufgabe
1) Vollziehen Sie die Analysen nach, deren Ausgaben wir in der Vorlesung besprochen haben.
- Schreiben Sie kurze Ergebnistexte zur Beantwortung der Fragen bzw. zum Test der Hypothesen:
- Wie hängen die TV- und Radionutzung mit dem politischen Wissen zusammen?
- Personen, die Twitter häufiger nutzen, beantworten mehr Fragen korrekt.
- Personen, die Facebook häufiger nutzen, beantworten weniger Fragen korrekt.
2) Vollziehen Sie die Analysen nach, die im Artikel in Tabellen 5 und 6 dargestellt sind.
- Wie lässt sich die wahrgenommene Personalisierung der eigenen Nachrichtenumgebung erklären?
- Wie lässt sich die wahrgenommene Informationsüberlastung erklären?
- BONUS: Überprüfen Sie, inwiefern das Modell die statistischen Annahmen erfüllt.
Lösung
- Zu 1) Siehe Code und Ausgaben aus der Vorlesung
- Zu 2) R Skript | HTML mit Output
7.5 Transkript
WarnungHinweise zum automatisiert erstellten Transkript
Das folgende Transkript wurde auf Basis der Aufzeichnung der Vorlesung erstellt. Die vollständigen Aufzeichnungen inklusive der Bildschirminhalte sind in Blackboard🔒 verfügbar. Die Tonspur wurde zuerst mit Hilfe der Werkzeuge des Oral-History.Digital Projekts wörtlich transkribiert. Die wörtliche Transkription wurde in Kombination mit den Vorlesungsfolien mithilfe von Sprachmodellen (v. a. Claude Sonnet 4.5 und GPT 5.2) zu einem übersichtlichen Transkript zusammengefasst. Im Anschluss wurde das Transkript von einer studentischen Hilfskraft überprüft, geglättet und ggf. angepasst. In diesem Prozess kann es an verschiedenen Stellen zu Fehlern kommen. Im Zweifel gilt das gesprochene Wort, und auch beim Vortrag mache ich Fehler.
Ich stelle das Transkript hier als experimentelles, ergänzendes Material zur Dokumentation der Vorlesung zur Verfügung. Noch bin ich mir unsicher, ob es eine sinnvolle Ergänzung ist und behalte mir vor, es weiter zu bearbeiten oder zu löschen.
Multiple lineare Regression
In dieser Sitzung der Veranstaltung „Methoden der empirischen Kommunikations- und Medienforschung“ wird die multiple lineare Regression als zentrales Verfahren eingeführt und vertieft. Aufbauend auf der zuvor behandelten bivariaten linearen Regression wird nun systematisch gezeigt, was passiert, wenn mehr als ein Prädiktor zur Erklärung einer abhängigen Variablen verwendet wird. Als durchgängiges Anwendungsbeispiel dient ein Artikel von Van Erkel & Van Aelst (2021), in dem politisches Wissen (political knowledge) unter anderem durch verschiedene Mediennutzungsvariablen erklärt wird.
- Forschungsbeispiel: Van Erkel & Van Aelst (2021), Political Communication, Online-Befragung in Flandern.
- Zentrale abhängige Variable: politisches Wissen (Index aus richtig beantworteten Wissensfragen, \(0–5\)).
- Zentrale Prädiktoren: Nutzung klassischer Medien (Radio, TV, Zeitungen, Online-Newsseiten), Social Media (Facebook, Twitter), sowie Kontrollvariablen wie Alter, Geschlecht, Bildung, politisches Interesse und wahrgenommene Informationsüberlastung.
Zur Einstimmung wird kurz auf die bivariate Regression zurückgeblickt, insbesondere auf die Übung zur Zeitungsnutzung als Prädiktor politischen Wissens. Die Frage war: Wie stark hängt die Häufigkeit der Zeitungsnutzung damit zusammen, wie viele Wissensfragen zu Politik korrekt beantwortet werden?
- In der bivariaten Regression zeigt der unstandardisierte Koeffizient für Zeitungsnutzung etwa \(0.3\): Pro zusätzlichem Skalenpunkt auf der Zeitungsnutzungsskala steigt die Zahl der richtig beantworteten Wissensfragen um etwa \(0.3\).
- Das zugehörige Konfidenzintervall enthält nur positive Werte und der \(p\)-Wert ist kleiner als \(0.01\), d. h. der Zusammenhang gilt als statistisch signifikant.
- Das \(R^2\) der bivariaten Regression beträgt etwa \(0.11\), also 11% erklärte Varianz des politischen Wissens allein durch die Zeitungsnutzung.
Diese Wiederholung dient dazu, die wichtigsten Größen (Koeffizient, Konfidenzintervall, \(p\)-Wert, \(R^2\)) zu verankern, die in der multiplen Regression wieder auftauchen werden.
Grundlagen der multiplen Regression
Warum überhaupt eine multiple Regression? In der sozialen Realität sind Phänomene wie politisches Wissen fast nie durch nur eine Variable erklärbar; es gibt meist mehrere Variablen, von denen man theoretisch annimmt, dass sie Einfluss nehmen. Man möchte etwa wissen, ob Alter oder Zeitungsnutzung „wichtiger“ ist, oder die Wirkung einer Variable unter Kontrolle anderer Variablen betrachten.
Ziele:
- Verbesserung der Erklärungsleistung des gesamten Modells.
- Verbesserung der Vorhersagequalität des Modells.
- Vergleich der Bedeutung verschiedener Zusammenhänge.
- Berücksichtigung von Drittvariablen bei Vergleichen.
- Mit zusätzlichen Annahmen: Schätzen kausaler Effekte mit nicht-experimentellen Daten.
- Modellierung von Wechselwirkungen (Moderation).
- Modellierung von mehrstufigen Zusammenhängen (Mediation, z. B. \(X \rightarrow M \rightarrow Y\)).
Mathematischer Rahmen und OLS-Schätzung
Technisch basiert die multiple Regression weiterhin auf der Methode der kleinsten Quadrate (OLS), genau wie die bivariate Regression. Ziel ist, eine Regressionsgerade (bzw. -hyperfläche) zu finden, die die quadrierten Abweichungen zwischen beobachteten und vorhergesagten Werten minimiert.
Allgemeine Regressionsgleichung für politisches Wissen mit mehreren Prädiktoren:
- \(\begin{aligned}\text{Political Knowledge} &= b_0 + \beta_1 \times \text{Radio} + \beta_2 \times \text{TV} + \beta_3 \times \text{Newspapers} \\&\quad + \beta_4 \times \text{Age} + \dots + \varepsilon\end{aligned}\)
Wesentliche Begriffe:
- Intercept (\(b_0\)): Vorhergesagter Wert von \(Y\), wenn alle Prädiktoren den Wert \(0\) haben. In vielen Anwendungen (z. B. Alter = \(0\) Jahre) ist das praktisch nicht sinnvoll interpretierbar; mathematisch wird er aber benötigt.
- Regressionskoeffizienten (\(b_1, b_2, \dots\)): Quantifizieren, wie stark sich \(Y\) ändert, wenn ein Prädiktor um 1 Einheit steigt, während alle anderen Prädiktoren konstant gehalten werden.
- Fehlerterm \(\varepsilon\): Umfasst die Unterschiede zwischen den beobachteten Werten und den vorhergesagten Werten der Regressionsgleichung.
In der Vorlesung wird betont, dass im einfachsten Fall zunächst ein additives Modell angenommen wird: Die Einflüsse der Prädiktoren werden einfach aufaddiert, ohne Wechselwirkungen.
Additives Modell und partielle Regressionskoeffizienten
Im additiven Modell werden alle Prädiktoren linear und ohne Interaktion aufgenommen, d. h. die Regressionsgleichung besteht aus einem Intercept und der Summe der Produkte „Koeffizient × Prädiktor“. Zwischen den einzelnen Prädiktoren steht nur ein Pluszeichen; die Effekte werden addiert.
Die Vorlesung bezeichnet die Koeffizienten in der multiplen Regression formal als partielle Regressionskoeffizienten. Sie quantifizieren den Beitrag einer Variable zur Erklärung von \(Y\) über alle anderen Variablen im Modell hinaus.
- Partielle Regressionskoeffizienten: Effekt einer Variable, wenn alle anderen Prädiktoren konstant gehalten werden (Kontrolle der übrigen Variablen).
- Alltagsbegriff: In der Praxis werden sie meist einfach “Regressionskoeffizienten” oder “Regressionsgewichte” genannt.
Diese partielle Sichtweise ist zentral, weil in multiplen Modellen immer Vergleiche unter Konstanthaltung der anderen Variablen interpretiert werden.
Beispiel: Politisches Wissen durch Alter und Zeitungsnutzung
Um den Übergang von bivariater zu multipler Regression nachvollziehbar zu machen, wird ein einfaches Modell mit zwei Prädiktoren betrachtet: Alter und Zeitungsnutzung als Erklärungsvariablen für politisches Wissen. Die passende Regressionstabelle zeigt u. a.:
- Intercept: etwa \(0.99\); 95%-Konfidenzintervall (\(0.67; 1.31\)); \(t(990) = 6.07\); \(p < 0.001\); Standardkoeffizient \(0.00\) (\(-0.06; 0.06\)).
- Alter: unstandardisierter Koeffizient \(0.02\); 95%-KI (\(0.02; 0.03\)); \(t(990) = 8.24\); \(p < 0.001\); standardisiert \(0.24\) (\(0.19; 0.30\)).
- Zeitungsnutzung: unstandardisierter Koeffizient \(0.22\); 95%-KI (\(0.18; 0.27\)); \(t(990) = 9.31\); \(p < 0.001\); standardisiert \(0.28\) (\(0.22; 0.33\)).
- Adjusted \(R^2\): \(0.16\).
Interpretation der unstandardisierten Koeffizienten:
- Alter: Wenn wir zwei Personen vergleichen, die sich im Alter um ein Jahr unterscheiden, aber gleich häufig die Zeitung nutzen, dann beantwortet die ältere Person im Mittel etwa \(0.02\) Fragen mehr korrekt.transkript-vl-9.docx+1
- Zeitungsnutzung: Wenn wir zwei gleich alte Personen betrachten, die sich in der Zeitungsnutzung um einen Skalenpunkt unterscheiden (z. B. „selten“ vs. „mittelfrequent“), dann beantwortet die Person mit der höheren Zeitungsnutzung im Mittel etwa \(0.22\) Fragen mehr korrekt.pdf-vl-9.pdf+1
Der Intercept von etwa \(0.99\) wäre formal die vorhergesagte Zahl korrekt beantworteter Fragen für eine Person, die \(0\) Jahre alt ist und nie Zeitung liest; da diese Kombination inhaltlich keinen Sinn ergibt, wird die Konstante hier nicht weiter interpretiert.
Standardisierte Koeffizienten und Vergleich der Effektstärken
In der gleichen Tabelle sind auch standardisierte Koeffizienten angegeben. Sie drücken die Zusammenhänge in Standardabweichungen aus und liegen typischerweise zwischen \(-1\) und \(+1\). Im bivariaten Fall entspricht der standardisierte Koeffizient der Pearson-Korrelation \(r\); in der multiplen Regression bleibt er ein Maß für die Stärke des Zusammenhangs, aber unter Kontrolle der anderen Variablen.
Im Beispielmodell sehen wir für Alter etwa einen standardisierten Koeffizienten von \(0.24\) und für Zeitungsnutzung von \(0.28\), mit stark überlappenden Konfidenzintervallen. Das lässt den Schluss zu, dass beide Variablen – bei Berücksichtigung der jeweils anderen – einen ähnlich starken positiven Zusammenhang mit politischem Wissen aufweisen.
- Standardisierte Koeffizienten helfen speziell dann, wenn Variablen unterschiedlich skaliert sind (Jahre vs. Skala 1–6), weil sie eine gemeinsame Skala (Standardabweichungen) herstellen.
- In der Praxis formuliert man eher qualitative Aussagen wie „mittelstarker positiver Zusammenhang“ oder vergleicht die Koeffizienten zueinander („Alter und Zeitungsnutzung sind ähnlich bedeutsam“), statt in Standardabweichungen zu rechnen.
Der Dozent empfiehlt, Standardabweichungen vor allem als Denkstütze zu nutzen: Man stelle sich z. B. eine Person mit durchschnittlicher Zeitungsnutzung und eine Person mit einem Wert eine Standardabweichung darüber vor und überlege, wie weit sich diese in \(Y\) verschieben würde.
Inferenzstatistik in der multiplen Regression
In der Regressionstabelle zu Alter und Zeitungsnutzung werden für jeden Koeffizienten Konfidenzintervalle, \(t\)-Werte und \(p\)-Werte angegeben. Getestet wird jeweils die Nullhypothese, dass der partielle Zusammenhang zwischen Prädiktor und politischem Wissen in der Grundgesamtheit Null ist.
- Konfidenzintervall: Bereich plausibler Werte; liegt \(0\) außerhalb des Intervalls, ist der Effekt bei der gewählten Irrtumswahrscheinlichkeit (z. B. 5%) signifikant.
- t-Wert und p-Wert: Der \(t\)-Wert ist der Koeffizient dividiert durch den Standardfehler; der \(p\)-Wert gibt an, wie wahrscheinlich ein so starker oder stärkerer Effekt unter der Nullhypothese wäre.
- In unserem Beispiel sind die \(p\)-Werte für Alter und Zeitungsnutzung sehr klein, sodass man von signifikanten positiven Zusammenhängen ausgeht.
Es wird betont, dass \(p\)-Werte und Konfidenzintervalle hier gleich interpretiert werden wie in der bivariaten Regression, nur dass es nun um partielle Zusammenhänge geht.
\(R^2\) und Adjusted \(R^2\)
Das \(R^2\) der multiplen Regression gibt an, wie viel Varianz der abhängigen Variable durch das gesamte Modell erklärt wird. Im Beispiel mit Alter und Zeitungsnutzung beträgt das Adjusted \(R^2\) etwa \(0.16\), d. h. 16% der Varianz des politischen Wissens werden gemeinsam durch diese beiden Prädiktoren erklärt.
Die Folien zeigen die geometrische Interpretation: \(R^2\) misst, wie viel näher die Regressionsgerade (bzw. -fläche) an den Datenpunkten liegt, verglichen mit einer „Vorhersage“ allein durch den Mittelwert.
Formelhaft ist auf den Folien angegeben:
\(R^2 = 1 - \frac{\sum (y_i - \hat{y}_i)^2}{\sum (y_i - \bar{y})^2} = 0.09\) in einem einfachen Beispiel.
Adjusted \(R^2\): \(R_{\text{korr}}^{2} = 1 - \frac{n-1}{n-k-1}(1 - R^{2})\), wobei \(n\) die Fallzahl und \(k\) die Anzahl der Prädiktoren ist.
\(\rightarrow\) \(R^2\) steigt automatisch, wenn man immer mehr Prädiktoren aufnimmt – auch dann, wenn sie in Wirklichkeit keinen systematischen Zusammenhang haben.
\(\rightarrow\) Im Extremfall könnte man bei \(n\) Fällen mit \(n-1\) Prädiktoren die Varianz perfekt erklären (Overfitting).
\(\rightarrow\) Adjusted \(R^2\) korrigiert diesen Effekt, indem es die Anzahl der Prädiktoren mit einbezieht und so „zufällige“ Passungen bestraft.transkript-vl-9.docx+1
Interpretatorisch bleibt es bei: Adjusted \(R^2\) ist der Anteil der Varianz der abhängigen Variable, der durch das Modell (unter Berücksichtigung der Komplexität) erklärt wird.
Inhaltliche Interpretation: Vergleiche und „Interventionen“
Die Vorlesung diskutiert zwei inhaltliche Interpretationsarten der multiplen Regression:
- Vergleichsperspektive:
- Wir vergleichen z. B. Personen, die sich in der Zeitungsnutzung um einen Skalenpunkt unterscheiden, aber gleich alt sind; das Modell sagt, dass die Person mit höherer Zeitungsnutzung etwa \(0.22\) mehr Fragen korrekt beantwortet.
- Gleichzeitig wissen wir, dass ältere Personen – bei gleicher Zeitungsnutzung – mehr Fragen richtig beantworten.
- Interventionsperspektive / (vorsichtige) Kausalinterpretation:
- Man kann sich vorstellen, eine Intervention zu planen: etwa Zeitungsabos zu verschenken, um Zeitungsnutzung zu erhöhen.
- Unter der Annahme, dass das Modell alle relevanten Einflüsse kontrolliert, könnte man die \(0.22\) als kausalen Effekt interpretieren: eine Erhöhung der Zeitungsnutzung um einen Punkt würde das politische Wissen um ca. \(0.22\) Fragen steigern.
- Es wird darauf hingewiesen, dass diese Annahme im einfachen Modell (nur Alter als weitere Variable) sehr gewagt ist, aber mit größeren Modellen theoretisch plausibler werden kann.
Die multiple Regression erlaubt also sowohl kontrollierte Vergleiche („gleiches Alter, unterschiedliche Zeitungsnutzung“) als auch hypothetische „Was-wäre-wenn“-Überlegungen, wenn man bereit ist, zusätzliche Kausalannahmen zu treffen.
Kategorielle Prädiktoren: Grundidee
Im nächsten Block geht es um kategoriale Prädiktoren. Die Folien betonen, dass die lineare Regression (bzw. das allgemeine lineare Modell) ein sehr flexibles Werkzeug ist, das bekannte Mittelwertvergleichsverfahren als Spezialfälle umfasst:
- \(t\)-Test: Vergleich von 2 Gruppenmittelwerten.
- Varianzanalyse: Mehrfaktorielle Experimentaldesigns.
Diese Verfahren sind statistisch äquivalent zur entsprechenden Regressionsmodellierung mit Dummy-Variablen. Für komplexere Analysen empfiehlt der Dozent, direkt in der Regressionslogik zu arbeiten, weil sich dort leichter zusätzliche Prädiktoren, Interaktionen usw. integrieren lassen.
In der Sitzung wird das Modell für politisches Wissen um zwei kategoriale Prädiktoren erweitert:
- Gender (zweistufig, binär).
- Education (dreistufig, ordinal: niedrig, mittel, hoch).
Diese sind auch in den Modellen von Van Erkel & Van Aelst enthalten.
Dummy-Codierung: Binäre Variable Gender
Zunächst wird die bekannte binäre Variable Gender aufgegriffen. Sie wird als Dummy-Variable operationalisiert, z. B.: \(female = 1\), sonst \(0\).
Die Folien zeigen die einfache Gleichung für einen binären Prädiktor:
- \(Y = \beta_0 + \beta_1 \times \text{female} + \varepsilon\)
Daraus ergeben sich zwei Fälle:
- Für \(female = 0\) (z. B. Männer): \(Y = b_0 + \varepsilon\).
- Für \(female = 1\) (z. B. Frauen): \(Y = b_0 + b_1 + \varepsilon\).
Interpretation:
- Intercept \(b_0\): Mittelwert der abhängigen Variable für die Referenzgruppe (hier: Personen mit \(female = 0\)).
- Koeffizient \(b_1\): Unterschied zwischen der Mittelwerten von Frauen und der Referenzgruppe.
In den Modellen von Van Erkel & Van Aelst sind die Koeffizienten für female z. B. etwa \(-0.48\) (Modell 1) bzw. \(-0.46\) (Modell 4), jeweils hoch signifikant. Das bedeutet: Frauen beantworten im Mittel rund eine halbe Wissensfrage weniger korrekt als Männer, selbst wenn andere Variablen im Modell kontrolliert werden.
Dummy-Codierung: Mehrstufige Variable Bildung
Komplexer wird es bei der dreistufigen Bildvariable (low, middle, high), für die mehrere Dummy-Variablen gebildet werden müssen. Allgemein gilt: Bei \(K\) Ausprägungen werden \(K-1\) Dummys benötigt.
Vorgehen nach dem Transkript:
- Referenzkategorie ist niedrige Bildung (low).
- Es werden zwei Dummy-Variablen gebildet: mittlere Bildung (\(1 = middle\), sonst \(0\)) und hohe Bildung (\(1 = high\), sonst \(0\)).
- Personen mit niedriger Bildung haben auf beiden Dummys den Wert \(0\); ihr Mittelwert ist im Intercept abgebildet.
- Der Koeffizient für mittlere Bildung gibt den Unterschied im politischen Wissen zwischen Personen mit mittlerer und niedriger Bildung an; analog der Koeffizient für hohe Bildung.
In der R-Regression, die nur Bildung als Prädiktor umfasst, ergeben sich z. B.:
- Koeffizient mittlere Bildung: ca. \(0.39\) – Personen mit mittlerer Bildung beantworten im Mittel \(0.39\) Fragen mehr als Personen mit niedriger Bildung.
- Koeffizient hohe Bildung: ca. \(0.67\) – Personen mit hoher Bildung beantworten im Mittel \(0.67\) Fragen mehr als Personen mit niedriger Bildung.
Diese Koeffizienten entsprechen genau den Differenzen der Gruppenmittelwerte, die zuvor deskriptiv berechnet wurden. Dazu kommen jeweils Signifikanztests (Konfidenzintervall, \(t\), \(p\)), mit denen sich z. B. feststellen lässt, dass Personen mit mittlerer Bildung signifikant mehr Fragen korrekt beantworten als Personen mit niedriger Bildung.
Wichtig: Aus dieser ersten Codierung kann man noch nicht ablesen, ob sich mittlere und hohe Bildung signifikant voneinander unterscheiden. Dafür muss man die Referenzkategorie wechseln.
Referenzkategorie wechseln und Post-hoc-Vergleiche
Um den Unterschied zwischen mittlerer und hoher Bildung zu testen, wird die Referenzkategorie in der Dummy-Codierung geändert. Die mittlere Bildung wird nun zur Referenz, und die Dummys kodieren niedrige und hohe Bildung.
- Personen mit mittlerer Bildung haben nun sowohl auf „niedrige Bildung“ als auch auf „hohe Bildung“ den Wert \(0\).
- Der Intercept ist nun der Mittelwert für Personen mit mittlerer Bildung.
- Der Dummy „niedrige Bildung“ hat einen Koeffizienten von \(-0.39\), was die Differenz zum neuen Referenzwert widerspiegelt (gleicher Betrag wie zuvor, aber negatives Vorzeichen).
- Der Dummy „hohe Bildung“ zeigt nun z. B. etwa \(+0.28\), was den Unterschied zwischen hoher und mittlerer Bildung quantifiziert.
Mit dieser Codierung erhält man einen Signifikanztest für den Unterschied zwischen mittlerer und hoher Bildung; im Beispiel ist dieser Unterschied signifikant. Die Logik ist dabei immer dieselbe: Jeder Dummy-Koeffizient steht für einen Mittelwertsunterschied zur aktuell gewählten Referenzkategorie.
Die Vorlesung betont, dass man in Publikationen (wie bei Van Erkel & Van Aelst) genau auf die angegebene Referenzkategorie achten muss, um die Tests richtig zu interpretieren. Aus der publizierten Tabelle mit „Level of education (ref = Low)“ lässt sich der Unterschied zwischen middle und high nicht direkt ablesen; er müsste nachträglich (z. B. durch Umcodierung oder Kontrasttests) geprüft werden.
Große Regressionsmodelle:
Im Abschnitt zu den „großen“ Regressionsmodellen werden komplexere Modelle mit vielen Prädiktoren betrachtet, insbesondere Modell 1 und Modell 4 aus Tabelle 4 von Van Erkel & Van Aelst.
Die R-Syntax für diese Modelle lautet:
- Modell 1:
m1 <- lm(Political_knowledge ~ Radio + Television + Newspapers + Online_news_sites + Twitter + Facebook + Gender + Age + Education + Political_interest, data = d)- Modell 4:
m4 <- lm(Political_knowledge ~ Radio + Television + Newspapers + Online_news_sites + Twitter + Facebook + Gender + Age + Education + Political_interest + Information_overload, data = d)Die Folie „Models 1 & 4“ zeigt die geschätzten Koeffizienten (mit Standardfehlern und Signifikanzniveau):
- Klassische Medien (TV, Newspapers, Online_news_sites) haben positive, meist signifikante Koeffizienten (z. B. Zeitungen ca. \(0.08\); Online-News ca. \(0.06\)).
- Facebook weist einen negativen und signifikanten Koeffizienten auf (ca. \(-0.07\) in beiden Modellen); Twitter ist negativ, aber nicht signifikant.
- Gender (female) hat einen negativen Koeffizienten (ca. \(-0.48\) bzw. \(-0.46\)); Frauen haben in diesem Datensatz niedrigere Werte im politischen Wissen.
- Alter ist positiv und signifikant (ca. \(0.02\) pro Jahr).
- Mittlere und hohe Bildung haben positive Koeffizienten (z. B. \(0.28\) und \(0.48\) in Modell 1).
- Politisches Interesse ist stark positiv und hoch signifikant (ca. \(0.18\) in Modell 1, \(0.17\) in Modell 4).
- Informationsüberlastung (nur in Modell 4) hat einen negativen Koeffizienten von etwa \(-0.03\), ebenfalls signifikant.
- Adjusted \(R^2\) liegt bei etwa \(0.371\) für Modell 1 und \(0.376\) für Modell 4.
Die ausführliche Regressionstabelle für Modell 4 zeigt zusätzlich Konfidenzintervalle und standardisierte Koeffizienten; sie bestätigt die Muster aus der kompakten Tabelle:
- Positiv und signifikant: TV, Newspapers, Online-News-Seiten, Alter, mittlere und hohe Bildung, politisches Interesse.
- Negativ und signifikant: Facebook, weibliches Geschlecht, Informationsüberlastung.
- Nicht signifikant: Radio, Twitter.
Inhaltlich lässt sich daraus ablesen, dass klassische Mediennutzung, höheres Alter, höhere Bildung und höheres politisches Interesse mit höherem politischem Wissen einhergehen, während Facebook-Nutzung, weibliches Geschlecht und Informationsüberlastung mit niedrigerem politischem Wissen zusammenhängen – unter Kontrolle aller anderen im Modell enthaltenen Variablen.
Zusammenfassung
Die Sitzung führt schrittweise von der bivariaten zur multiplen Regression und verbindet Transkript und Folien zu einem konsistenten Bild:
- Multiple Regression ist eine Erweiterung der linearen Regression, bei der mehrere Prädiktoren gleichzeitig berücksichtigt werden, um Erklärungsleistung, Vorhersagequalität und Vergleichbarkeit von Effekten zu erhöhen.
- Partielle Regressionskoeffizienten quantifizieren Effekte unter Kontrolle der übrigen Variablen; standardisierte Koeffizienten ermöglichen den Vergleich der Effektstärken über unterschiedlich skalierte Variablen.
- \(R^2\) und Adjusted \(R^2\) messen die erklärte Varianz des Gesamtmodells; Adjusted \(R^2\) korrigiert für die Anzahl der Prädiktoren.
- Kategoriale Prädiktoren werden über Dummy-Codierung in die Regression integriert; ihre Interpretation hängt von der gewählten Referenzkategorie ab.
- Anhand der Studie von Van Erkel & Van Aelst wird gezeigt, wie man konkrete Forschungsfragen (hier: Mediennutzung und politisches Wissen) mit multiplen Regressionsmodellen beantwortet und sorgfältig interpretiert.
Multiple lineare Regression – Teil 2
In der letzten Sitzung wurde die multiple lineare Regression eingeführt und am Beispiel von Van Erkel und Van Aelst gezeigt, wie ein größeres Regressionsmodell mit mehreren Mediennutzungsvariablen, Kontrollvariablen und politischem Wissen interpretiert wird. In dieser Sitzung geht es darum, diese Modelle noch besser zu lesen, anschaulich darzustellen und ihre Annahmen zu überprüfen.
Modell 4 von Van Erkel und Van Aelst
Im Zentrum steht erneut Modell 4 aus der Studie von Van Erkel und Van Aelst, mit dem untersucht wird, ob und wie Social-Media-Nutzung mit politischem Wissen zusammenhängt. Die abhängige Variable ist politisches Wissen, gemessen als Index aus fünf Wissensfragen.
Das Modell berücksichtigt mehrere Gruppen von Prädiktoren gleichzeitig: klassische Mediennutzung, Social-Media-Nutzung sowie Kontroll- und Hintergrundvariablen wie Geschlecht, Alter, Bildung, politisches Interesse und Information Overload. Dadurch wird nicht nur ein bivariater Zusammenhang betrachtet, sondern der partielle Effekt jeder Variable unter Kontrolle der anderen.
Regressionstabelle lesen
Die ausführliche Regressionstabelle enthält für jeden Prädiktor den unstandardisierten Koeffizienten, das 95%-Konfidenzintervall, den \(t\)-Wert, den \(p\)-Wert sowie standardisierte Koeffizienten. Der unstandardisierte Koeffizient beschreibt die Veränderung der abhängigen Variable in Originaleinheiten, wenn sich ein Prädiktor um eine Einheit verändert und alle anderen Variablen konstant gehalten werden.
Für Facebook zeigt die Tabelle einen negativen Koeffizienten. Das bedeutet: Häufigere Facebook-Nutzung ist mit geringerem politischem Wissen verbunden. Der Effekt ist statistisch signifikant, weil der \(p\)-Wert sehr klein ist und das Konfidenzintervall vollständig unter null liegt.
Die Tabelle zeigt außerdem positive Zusammenhänge für Fernsehen, Zeitungen und Online-News-Seiten sowie negative Zusammenhänge für Facebook und Information Overload. Twitter ist in diesem Modell nicht signifikant, weil das Konfidenzintervall die Null einschließt.
Wichtige Begriffe
- Unstandardisierter Koeffizient: Änderung in den Originaleinheiten der abhängigen Variable.
- \(p\)-Wert: Test darauf, ob der beobachtete Zusammenhang statistisch mit einer Nullhypothese vereinbar ist.
- Konfidenzintervall: Bereich plausibler Werte für den wahren Effekt.
- Standardisierter Koeffizient: Effekt auf einer vergleichbaren Skala in Standardabweichungen.
Koeffizientenplot
Ein Koeffizientenplot stellt dieselben Informationen wie die Regressionstabelle grafisch dar. Der Punkt markiert den Punktschätzer, die Linie zeigt das 95%-Konfidenzintervall.
Der Vorteil dieser Darstellung ist, dass man schnell erkennt, welche Prädiktoren positiv oder negativ mit dem Outcome zusammenhängen und wie groß die Unsicherheit ist. Statistische Signifikanz erkennt man daran, ob das Konfidenzintervall die Null schneidet oder nicht.
Die Vorlesung betont, dass diese Darstellung besonders hilfreich ist, weil sie Muster schneller sichtbar macht als viele Einzelzahlen in einer Tabelle. Gerade bei größeren Modellen ist das übersichtlicher.
Standardisierte Koeffizienten
Der standardisierte Koeffizientenplot zeigt dieselben Zusammenhänge, aber auf einer Skala in Standardabweichungen. Das erleichtert den Vergleich der relativen Stärke verschiedener Prädiktoren.
In der Vorlesung wird hervorgehoben, dass politisches Interesse besonders stark mit politischem Wissen zusammenhängt, wenn man standardisierte Koeffizienten betrachtet. Auch hier bleibt die Richtung der Effekte gleich: klassische Medien eher positiv, Facebook negativ.
Wichtig ist dabei: Kategoriale Variablen wie Geschlecht oder Bildung werden nicht „standardisiert“ wie metrische Variablen. Der Vergleich bleibt inhaltlich derselbe; standardisiert wird nur die metrische Seite beziehungsweise die abhängige Variable.
Vorhersagen für Prädiktoren
Mit einem Regressionsmodell kann man Vorhersagen für bestimmte Werte eines Prädiktors berechnen. Dafür setzt man für alle anderen Variablen typische Werte ein und variiert nur den interessierenden Prädiktor.
Für metrische Variablen nimmt man meist den Mittelwert, für kategoriale Variablen den Modus oder eine Referenzkategorie. So lässt sich zum Beispiel vorhersagen, wie viel politisches Wissen Personen mit unterschiedlicher Facebook-Nutzung voraussichtlich haben.
Im Beispiel sinkt das vorhergesagte politische Wissen mit steigender Facebook-Nutzung schrittweise. Dadurch wird der Koeffizient inhaltlich anschaulich, weil er nicht nur als Zahl, sondern als konkrete Vorhersage interpretierbar wird.
Vergleiche einzelner Ausprägungen
Die Vorlesung zeigt auch direkte Vergleiche zwischen Ausprägungen eines Prädiktors. Das ist besonders wichtig bei kategorialen Variablen wie Bildung oder Geschlecht.
Bei Bildung dient die niedrige Bildung als Referenzkategorie. Im Vergleich dazu geht mittlere Bildung mit mehr richtig beantworteten Wissensfragen einher, hohe Bildung noch stärker.
Beim Geschlecht wird ein Vergleich zwischen Frauen und Männern gezeigt, wobei Frauen im Modell weniger Wissensfragen richtig beantworten. Auch bei Facebook wird ein Vergleich zwischen niedriger und hoher Nutzung beschrieben.
Average Counterfactual Comparison
Die Average Counterfactual Comparison ist eine modernere Form der Modellinterpretation. Dabei wird gefragt, wie sich die Vorhersagen verändern würden, wenn alle Personen im Datensatz einmal in die eine und einmal in die andere Bedingung gesetzt würden.
Im Beispiel Geschlecht werden alle Fälle zunächst als weiblich und dann als männlich gesetzt; anschließend werden die vorhergesagten Werte verglichen. Der Durchschnitt dieser Unterschiede ergibt den kontrafaktischen Vergleich.
Für Facebook wird dieselbe Logik auf unterschiedliche Nutzungsniveaus übertragen, etwa auf unterdurchschnittliche versus überdurchschnittliche Nutzung. Das kommt einer kausalen Interpretation näher, auch wenn dafür starke Annahmen nötig sind.
Annahmen der Regression
Die Vorlesung erinnert daran, dass lineare Regression nur unter bestimmten Annahmen sinnvoll interpretiert werden kann. Dazu gehören Linearität, Normalverteilung und Homoskedastizität der Residuen, Unabhängigkeit der Residuen, keine einflussreichen Ausreißer und keine problematische Multikollinearität.
Gleichzeitig wird betont, dass OLS-Regression in der Praxis recht robust ist. Kleine Verletzungen führen also nicht sofort dazu, dass die Analyse wertlos wird.
Linearität
Linearität bedeutet, dass die Beziehung zwischen Prädiktoren und vorhergesagten Werten keinen systematischen Kurvenverlauf zeigt. In den Residualplots sollte die Referenzlinie daher möglichst flach und horizontal verlaufen.
Im Beispiel aus der Vorlesung wirkt diese Annahme insgesamt erfüllt, auch wenn an den Randbereichen leichte Abweichungen sichtbar sind. Das bedeutet, dass das Modell in extremen Vorhersagebereichen etwas schwächer sein kann.
Normalverteilung und Homoskedastizität
Die Residuen sollen ungefähr normalverteilt sein und über den Vorhersagebereich hinweg eine ähnliche Streuung haben. Homoskedastizität bedeutet, dass die Fehler nicht in manchen Bereichen systematisch größer sind als in anderen.
In der Vorlesung wird gezeigt, dass die Residuenverteilung im multiplen Modell deutlich besser aussieht als in der bivariaten Regression. Das liegt daran, dass das Modell durch die vielen Prädiktoren feinere Vorhersagen machen kann.
Unabhängigkeit der Residuen
Unabhängigkeit der Residuen bedeutet, dass die Fehler nicht systematisch miteinander zusammenhängen. Im passenden Diagnoseplot sollten die Punkte möglichst entlang der Referenzlinie liegen.
Im gezeigten Modell werden keine großen Probleme gesehen. Die Punkte folgen der Linie insgesamt ausreichend gut, sodass die Annahme als akzeptabel beschrieben wird.
Einflussreiche Ausreißer
Einflussreiche Ausreißer sind einzelne Fälle, die die Regressionslinie stark verzerren könnten. Besonders relevant sind hier Leverage- und Residualplots.
Im Beispiel liegen die Fälle innerhalb der Konturlinien, sodass keine gravierenden einflussreichen Ausreißer sichtbar sind. Das Modell wird daher in dieser Hinsicht als unproblematisch beschrieben.
Multikollinearität
Multikollinearität bedeutet, dass Prädiktoren stark miteinander korrelieren. Dadurch wird es schwieriger zu interpretieren, welchen Anteil jeder einzelne Prädiktor tatsächlich beiträgt.
Die Vorlesung betont, dass solche Zusammenhänge in sozialwissenschaftlichen Daten normal und erwartbar sind. Es ist also nicht realistisch, dass alle Variablen völlig unabhängig voneinander sind.
Wichtig ist aber: Multikollinearität betrifft vor allem die beteiligten Variablen selbst und nicht automatisch das gesamte Modell. Wenn die zentralen Forschungsvariablen nicht betroffen sind, kann das Modell trotzdem sinnvoll geschätzt werden.
Multikollinearität prüfen
Als erste Möglichkeit wird eine Korrelationsmatrix zwischen den Prädiktoren gezeigt. Dort sieht man zum Beispiel, dass Fernsehen und Radio relativ stark zusammenhängen, ebenso andere Medienvariablen in unterschiedlichem Ausmaß.
Als zweite Möglichkeit wird der Variance Inflation Factor, kurz VIF, vorgestellt. Er zeigt vereinfacht, wie gut ein Prädiktor durch die anderen Prädiktoren erklärt werden kann.
Als grobe Regel wird erwähnt, dass Werte unter 5 meist unproblematisch sind. Höhere Werte deuten darauf hin, dass eine Variable redundant werden könnte.
Die Dozierende äußert aber Skepsis gegenüber einem rein datengetriebenen Entfernen von Variablen nur wegen hoher Kollinearität. Theoretische Argumente bleiben zentral.
Übungsaufgaben
Am Ende der Vorlesung werden Übungsaufgaben eingesetzt, um die Interpretation von Regressionsoutputs zu trainieren. Die Studierenden sollen aus Tabellen und Grafiken ableiten, welche Aussagen richtig sind und wie man Koeffizienten korrekt liest.