1 Hallo
1.1 Folien
1.2 Code und Ausgaben aus der Vorlesung
Beispiel: Daten laden, aufbereiten und Regressionsmodell schätzen
library(tidyverse)── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.2.0 ✔ readr 2.1.6
✔ forcats 1.0.1 ✔ stringr 1.6.0
✔ ggplot2 4.0.2 ✔ tibble 3.3.1
✔ lubridate 1.9.4 ✔ tidyr 1.3.2
✔ purrr 1.2.1
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errorsd <- haven::read_sav(here::here("data/Voegele_Bachl_2017.sav")) |> # Daten lesen
mutate( # Daten aufbereiten
schwab = as_factor(c_0001), # Treatment
gesamt = v_126 # Gesamtbewertung des Politikers
)
m <- lm(gesamt ~ schwab, data = d) # Regressionsmodell schätzenBeispiel: Regressionstabelle anzeigen
report::report_table(m, metrics = "R2_adj", include_effectsize = FALSE)Parameter | Coefficient | 95% CI | t(361) | p | Fit
---------------------------------------------------------------------------
(Intercept) | 3.81 | [ 3.67, 3.94] | 55.54 | < .001 |
schwab [schwäbisch] | -0.20 | [-0.39, -0.02] | -2.22 | 0.027 |
| | | | |
R2 (adj.) | | | | | 0.01Beispiel: Ergebnisse grafisch darstellen
marginaleffects::plot_predictions(m, by = "schwab") + theme_minimal()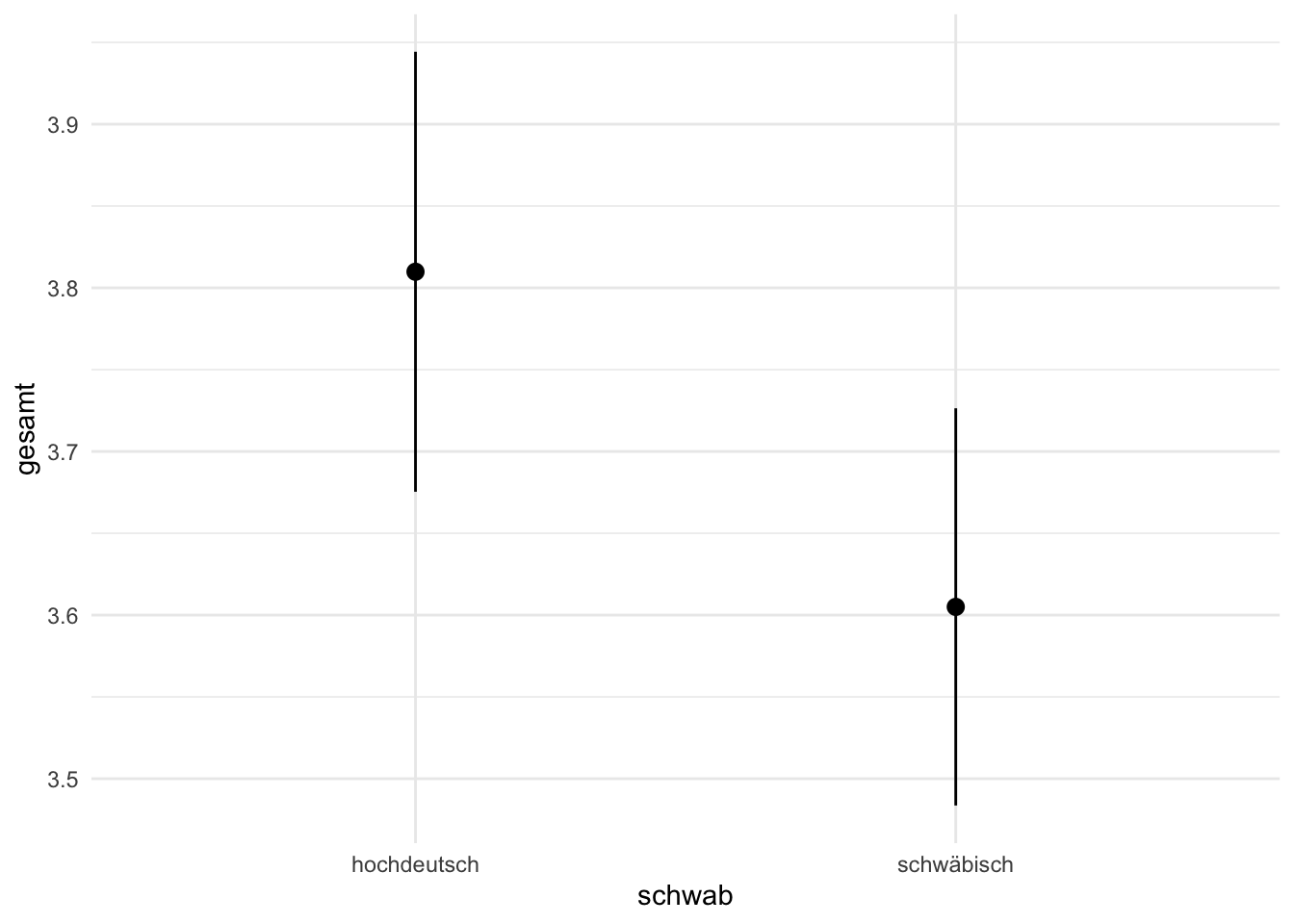
1.3 Hausaufgabe
Hausaufgabe (1/3)
Klären Sie, wie Sie R und RStudio für die Übungen zur Vorlesung nutzen können.
- Beste Variante: Installation auf eigenem Computer (RStudio, R)
- Alternative 1: Virtueller, Browser-basierter Zugang zu einer Workstation der Arbeitsstelle [FOLGT]
- Alternative 2: Nutzung der öffentlichen Computerräume (z.B. FUB-IT, Bibliothek)
- Alternative 3: Nutzung eines kostenlosen Accounts auf Posit.Cloud
- Alternative 4: Browser-basierte R-Version
Hausaufgabe (2/3)
Fügen Sie den folgenden Code ein und führen Sie ihn aus. Wenn Sie ein Histogramm sehen, ist Ihr Gerät bereit für die Vorlesung.
rnorm(100) |> hist()Hausaufgabe (3/3)
Lesen Sie Van Erkel & Van Aelst (2021), insbesondere den Methodenteil. Mit den Daten aus dieser Studie werden wir uns in den nächsten Sitzungen beschäftigen.
Lösung
1.4 Transkript
WarnungHinweise zum automatisiert erstellten Transkript
Das folgende Transkript wurde auf Basis der Aufzeichnung der Vorlesung erstellt. Die vollständige Aufzeichnungen inklusive der Bildschirminhalte sind in Blackboard🔒 verfügbar. Die Tonspur wurde mit VoiceAI transkribiert. Das Transkript wurde dann mit Sprachmodellen (v.a. Claude Sonnet 4.5) geglättet und formatiert. In diesem Prozess kann es an verschiedenen Stellen zu Fehlern kommen. Im Zweifel gilt das gesprochene Wort, und auch beim Vortrag mache ich Fehler.
Ich stelle das Transkript hier als experimentelles, ergänzendes Material zur Dokumentation der Vorlesung zur Verfügung. Noch bin ich mir unsicher, ob es eine sinnvolle Ergänzung ist und behalte mir vor, es weiter zu bearbeiten oder zu löschen.
Begrüßung und Vorstellung
Die Vorlesung “Methoden der empirischen Kommunikations- und Medienforschung” richtet sich an Masterstudierende am Institut für Publizistik und Kommunikationswissenschaft der FU Berlin. Dozent ist Marko Bachl, Juniorprofessor für Digitale Forschungsmethoden an der FU Berlin seit Mai 2023.
Die Vorlesung wird aufgezeichnet und den Studierenden zur Verfügung gestellt. Marko Bachl war zuvor an der Universität Hohenheim tätig, wo er promovierte und als Postdoc arbeitete, sowie an der Hochschule für Musik, Theater und Medien Hannover und der Universität Augsburg.
Die Position als Juniorprofessor bedeutet eine vorläufige Professur mit zwei Evaluationen nach drei und sechs Jahren. Es handelt sich um eine vorgezogene Nachfolge für Professor Joachim Trebbe, der bisher die Methodenvorlesungen durchführte. Im Rahmen dieser Nachfolge wird das Modul neu gestaltet.
Motivation: Warum Forschungsmethoden?
Es gibt drei wesentliche Gründe für die Auseinandersetzung mit empirischen Forschungsmethoden im Masterstudium:
Wissenschaftliche Lektürekompetenz: Aktuelle Forschung in der Kommunikationswissenschaft verwendet fortgeschrittene Methoden, die über das Bachelor-Niveau hinausgehen. In aktuellen Publikationen, beispielsweise im Journal of Communication, finden sich Studien mit Grounded Theory Approach, Meta-Analysen mit Random-Effects-Modellen, Mehrebenenregressionen mit dichotomen abhängigen Variablen, Textual Analysis und Negative Binomial Regression. Um wissenschaftliche Literatur für Seminar- und Masterarbeiten verstehen zu können, ist ein Verständnis solcher Methoden unerlässlich.
Anwendungskompetenz: In der Vorlesung werden Analysen anhand der Programmiersprache R durchgeführt, meist basierend auf publizierten Studien. Die Studierenden erhalten Code-Beispiele, die sie nachvollziehen und anpassen können. Das Ziel ist ein Einstieg in die praktische Anwendung, sodass sie später in Forschungsprojekten und Masterarbeiten darauf aufbauen können, um nach weiterer Einarbeitung eigenständig Analysen durchführen zu können.
Alltagswissen: Der kompetente Umgang mit empirischen Informationen und Studienergebnissen wird immer wichtiger. Dies betrifft sowohl die Produktion als auch die Konsumption empirischer Evidenzen. Im Kontext von Misinformation, Disinformation und False Information ist es wichtig zu verstehen, wie empirische Evidenzen entstehen und wie sie zu bewerten sind. Auch das Verständnis von KI-Systemen als große statistische Modelle, die an Daten trainiert wurden, wird durch methodische Grundlagen erleichtert. Eine gewisse Code-Literacy ist heute eine wichtige wissenschaftliche und gesellschaftliche Kompetenz.
Programmiersprache R: Die Vorlesung verwendet R als freie und offene Software. R ist eine der beiden großen Sprachen für die Arbeit mit Daten (neben Python), ist “free as in freedom” und vielfältig einsetzbar. Alle Kursmaterialien, einschließlich der Folien und der Website, wurden mit R und Quarto erstellt.
Zusammenfassend dient die Vorlesung dazu, wissenschaftliche Studien verstehen, kritisieren und selbst durchführen zu können. Pragmatisch ist der Inhalt zudem prüfungsrelevant, da am Ende eine Klausur geschrieben wird.
Vorkenntnisse der Studierenden
Mittels einer Online-Befragung wurden die Vorkenntnisse der Studierenden erhoben, um die Vorlesung entsprechend anpassen zu können.
Aufbau des Moduls
Das Modul “Methoden” besteht aus zwei Vorlesungen und einer Methodenübung. Die erste Vorlesung findet im Wintersemester statt, die zweite im darauffolgenden Sommersemester. Das Modul umfasst insgesamt 15 Credits.
Modulstruktur laut Studien- und Prüfungsordnung: Das Modul kombiniert Vorlesungen im klassischen Format mit praktischen Methodenübungen, in denen eine spezielle Methode vertieft wird.
Die Herausforderung: Die Studierenden bringen sehr unterschiedliche Niveaus an Statistikkenntnissen mit.
Neu gestaltete Vorlesungen: Die Vorlesung wird aktuell neu gestaltet. Studierende werden ermutigt, sich einzubringen, Fragen zu stellen und Feedback zu geben. Bei zu schnellem Sprechen sollen sie dies mitteilen.
Lernziele
Die Vorlesung verfolgt drei zentrale Lernziele:
- Lektürekompetenz: Empirische Studien verstehen
- Kritikkompetenz: Empirische Studien beurteilen
- Anwendungskompetenz: Einstieg in die Durchführung empirischer Studien
Voraussetzungen
Folgende Kenntnisse werden vorausgesetzt:
- Kenntnisse der grundlegenden Verfahren der Datenerhebung (Befragung, Inhaltsanalyse, Beobachtung, experimentelle und nicht-experimentelle Designs)
- Kenntnisse der uni- und bivariaten Datenanalyse, besonders lineare Regression
- Grundsätzliches Verständnis der frequentistischen Inferenzstatistik
- Bereitschaft, sich eigenständig mit R zu beschäftigen: Verstehen, Bearbeiten und Ausführen einfacher Befehle zur Datenanalyse sowie Interpretation der Ausgaben
Zu den ersten beiden Punkten wird es Wiederholungssitzungen geben.
Leistungen und Prüfungsmodalitäten
Vorlesung: Es besteht keine Anwesenheitspflicht, aber auch keine Nachhilfepflicht für den Dozenten. Fragen zum Vorlesungsstoff werden gerne beantwortet, jedoch sollten keine Wiederholungen der gesamten Vorlesung angefordert werden.
Aktive Teilnahme: Es gibt Übungsaufgaben auf Vertrauensbasis. Die Studierenden bestätigen per Selbstauskunft im Blackboard, dass sie die Aufgaben bearbeitet haben. Die Übungsaufgaben sind klausurrelevant.
Klausur: Die Gesamtmodulprüfung ist eine 120-minütige E-Examination nach der zweiten Vorlesung im Sommersemester, voraussichtlich in der ersten Woche nach der Vorlesungszeit. Die Klausur umfasst den Stoff beider Vorlesungen.
Praktische Übungen
Die Vorlesung enthält praktische Übungen, meist auf Basis publizierter Studien. Es werden kurze Besprechungen in der Vorlesung durchgeführt, meist mit exemplarischen Analysen. R-Code zum Replizieren der Analysen wird zur Verfügung gestellt, sodass Studierende die Analysen zu Hause oder während der Vorlesung nachvollziehen können. Lösungen werden veröffentlicht. Das Ziel ist der Einstieg in die Anwendungskompetenz durch Anpassung von bestehendem Code.
Material
Das Material der Vorlesung ist Work in Progress und wird laufend aktualisiert. Das meiste Material findet sich auf der Kurs-Website, weiteres Material ist im Blackboard verfügbar. Die Website enthält Folien, Code und Output. Nicht öffentlich teilbare Daten befinden sich im geschlossenen Bereich des Blackboard.
Die Kurs-Website ist unter der angegebenen URL erreichbar. Sie enthält den Syllabus mit allen wichtigen Informationen.
Vorlesungsplan
Wintersemester: Das Wintersemester beginnt mit Wiederholungssitzungen zu univariater und bivariater Datenbeschreibung sowie einer R-Einführung. Anschließend werden verschiedene Analyseverfahren behandelt, darunter lineare Regression, logistische Regression und Mehrebenenmodelle. Weitere Themen sind Open Science, agentenbasierte Simulationen (Gastvortrag von Prof. Anne Waldherr, Universität Wien), Erhebung digitaler Forschungsdaten, automatisierte Inhaltsanalysen mit Large Language Models und die Messung von Online-Verhalten.
Sommersemester: Das Sommersemester wird fortgeschrittene qualitative Methoden wie Diskursanalyse und weitere Verfahren behandeln. Zudem sind explorative Computational Methods wie Topic Models geplant. Die genaue Planung befindet sich noch in der frühen Phase und kann sich verändern.
Empfohlene Literatur und Materialien
Es wurde eine Sammlung empfohlener Literatur zusammengestellt. Die Studierenden werden ermutigt, in verschiedene Materialien hineinzulesen und den Stil zu finden, der ihnen am besten gefällt. Die Bandbreite reicht von anwendungsorientierten Büchern bis zu theoretischen Werken mit mathematischen Herleitungen.
Für Grundlagen der Datenerhebung wird beispielsweise Brosius et al. empfohlen, der einen guten Überblick über Inhaltsanalyse, Experimente und andere Methoden bietet. Weitere Empfehlungen betreffen vertiefende Literatur zu quantitativen und qualitativen Methoden.
Rahmenbedingungen
Drei wichtige Rahmenbedingungen wurden genannt:
Nutzung von KI-Tools: KI-Tools wie ChatGPT können hilfreich sein, sollten aber sinnvoll eingesetzt werden. Es wird nicht empfohlen, Übungsaufgaben einfach in ein KI-Tool zu kopieren und den generierten Code zu übernehmen, ohne ihn zu verstehen. Sinnvoller ist es, KI-Tools zur Erklärung von Code zu nutzen, beispielsweise um einzelne Codezeilen verstehen zu lassen.
Inklusion und Diversität: Alle Studierenden sollen sich willkommen fühlen und mit ihren unterschiedlichen Erfahrungen und Hintergründen teilnehmen können. Bei Problemen können sich Studierende an den Dozenten wenden, auch über andere Personen, falls direkte Ansprache nicht gewünscht ist.
Psychische Gesundheit: Das Studium kann belastend sein. Es gibt Unterstützungsangebote wie Mental Wellbeing Support Points (niedrigschwellig, ohne Termin) und psychologische Betreuung an der FU Berlin.
Kontakt und Erreichbarkeit
Der Dozent ist jeden Montag in der Vorlesung erreichbar. Während der Vorlesungszeit können Termine über ein Online-Buchungssystem vereinbart werden. Alternativ ist Kontakt per E-Mail möglich.
Blackboard
Im Blackboard finden sich folgende Elemente:
- Link zum Syllabus auf der Kurs-Website
- Online-Forum für Fragen zum Vorlesungsstoff
- Forum für YouTube-Links (Musik für den Einstieg in kommende Sitzungen)
- Datensätze, die nicht öffentlich geteilt werden können
- Selbstreport-System für die aktive Teilnahme
Für Studierende ohne Möglichkeit, R auf dem eigenen Rechner zu installieren, gibt es eine RStudio-Workstation, die über den Webbrowser genutzt werden kann.
Ausblick auf die nächste Sitzung
In der nächsten Sitzung beginnt die Wiederholung mit der Beschreibung von Daten. Es wird erläutert, wie R funktioniert, wie Code gelesen und ausgeführt werden kann.