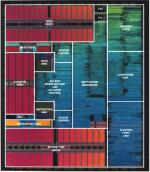
G3-Die (größer) |

G4-Die (größer) |
Änlich Intels MMX-Erweiterung für die Pentium-Reihe hat nun auch Motorola eine entsprechende Erweiterung für die PowerPC-Reihe entwickelt. Wie bei MMX handelt es sich auch bei AltiVec um eine Vektorrecheneinheit. Neben den typischen Anwendungen wie Grafik und Multimedia ist AltiVec im Gegensatz zu MMX aber auch auf die Verarbeitung von IP-Telefonie-, Spracherkennungs- und Netzwerk-Diensten ausgelegt. Obwohl PowerPC-Prozessoren bereits ohne AltiVec in Multimedia-Test besser abschnitten als vergleichbare Pentiums mit MMX (Quelle: c't), hat sich Motorola nun zur Einführung von AltiVec entschlossen. IBM hingegen unterstützt AltiVec nicht, so daß Motorola und IBM, die zusammen mit der Entwicklung des PowerPC begannen, zumindest teilweise in unterschiedliche Richungen weiterentwickeln.
Wie hoch der Stellenwert ist, der der AltiVec-Erweiterung eingeräumt
wird, sieht man schon beim Vergleich der Prozessor-Dies des G3- und des
G4-Prozessors:
|
G3-Die (größer) |
G4-Die (größer) |
Das gesamte obere Viertel des G4-Dies wird von der neuen Vektorrecheneinheit
eingenommen. Da die Ausnutzung der Fläche des Dies einer der wesentlichen
Kostenfaktoren eines Prozessors ist, wird deutlich, daß Motorola
der neuen Vektorrecheneinheit eine sehr hohe Bedeutung zumißt. Über
die tatsächliche Leistungsfähigkeit läßt sich bis
jetzt jedoch noch nichts genaues sagen, Apple verspricht aber, G4-Macs
seinen bei "Real Life"-Anwendungen im Schnitt doppelt so schnell wie G3-Rechner.
Ein Programm von Research Systems, mit dem die NASA Bildverarbeitung betreibt
zeigte nach Anpassung an die AltiVec-Einheit eine Performance-Gewinn um
den Faktor 5 (Quelle c't).
Das Haupteinsatzgebiet der PowerPC-Prozessoren liegt jedoch weniger
bei wissenschaftlichen Berechungen als bei Multimediaanwendungen und kleineren
(speziell Kommunikations-) Servern. Dementsprechend ist auch die AltiVec-Erweiterung
auf Bild-, Video- und Sprachverarbeitung ausgelegt, besonders erwähnt
wird immer wieder die IP-Telefonie. In diesen Bereichen ist es sinnvoll,
die Länge der verarbeiteten Vektoren, und damit die Anzahl der gleichzeitig
verarbeiteten Operanden, gegenüber den sehr lange Vektoren der älteren
Vektorrechner deutlich zu reduzieren: Die AltiVec-Einheit führt maximal
16 Befehle "parallel" aus, d.h. ein Vektor besteht aus maximal 16 Elementen.
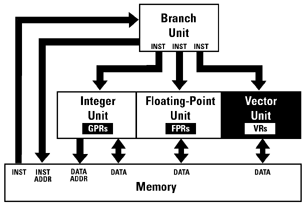 Die
AltiVec-Einheit (im Bild "Vector Unit") bildet eine neue unabhängige
Execution Unit, gleichwertig zu den beiden Integer Units (im Bild zusammengefaßt)
und der Floating-Point Unit. Genau wie die bereits beschiebenen Einheiten
arbeitet die neue Vector Unit unabhängig und parallel zu den anderen
Execution Units. Sie besteht intern sogar aus zwei wiederum voneinander
unabhängigen Einheiten, einer Vektor-ALU und einer zweiten Einheit,
die für Permutationen zuständig ist.
Die
AltiVec-Einheit (im Bild "Vector Unit") bildet eine neue unabhängige
Execution Unit, gleichwertig zu den beiden Integer Units (im Bild zusammengefaßt)
und der Floating-Point Unit. Genau wie die bereits beschiebenen Einheiten
arbeitet die neue Vector Unit unabhängig und parallel zu den anderen
Execution Units. Sie besteht intern sogar aus zwei wiederum voneinander
unabhängigen Einheiten, einer Vektor-ALU und einer zweiten Einheit,
die für Permutationen zuständig ist.
Die AltiVec-Einheit verarbeitet 128 Bit Vektoren. Sie besitzt 32 eigene
128-Bit breite Register und einen ebenso breiten Bus zum Hauptspeichern,
so daß mit einem Load-Befehl ein kompletter Vektor in ein Register
geladen werden kann. Dieser Bus bewältigt bei 200 MHz maximal 3,2
GByte/s.
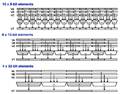 Für
die Aufteilung der Daten innerhalb eines 128-Bit-Vektors gibt es zahlreiche
Möglichkeiten: Genügt eine Genauigkeit von 8 Bit pro Element,
so können 16 Elemente in einen Vektor untergebracht und parallel verarbeitet
werden. Wie zu erwarten lassen sich die 128 Bit auch in 8 16-Bit-Elemente
oder 4 32-Bit-Elemente aufteilen. Bei jeder dieser Möglichkeiten kann
man zwischen vorzeichenlosen und vorzeichenbehafteten Integer-Werten wählen.
Neben diesen zu erwartenden Möglichkeiten, besteht auch die Möglichkeit
4 32-Bit-Fließkommazahlen in einem Vektor unterzubringen. Die Vektor-ALU
beherrscht also sowohl Integer- als auch FP-Operationen, wodurch sich erahnen
läßt, woher der beachtliche Platzbedarf der Einheit rührt
(siehe links oben auf dem G4 Die). Außerdem wird deutlich, worin
sich die enorme Anzahl neuer Befehle begründet: Viele Befehle unterscheiden
sich nur im verwendeten Datentypen voneinander.
Für
die Aufteilung der Daten innerhalb eines 128-Bit-Vektors gibt es zahlreiche
Möglichkeiten: Genügt eine Genauigkeit von 8 Bit pro Element,
so können 16 Elemente in einen Vektor untergebracht und parallel verarbeitet
werden. Wie zu erwarten lassen sich die 128 Bit auch in 8 16-Bit-Elemente
oder 4 32-Bit-Elemente aufteilen. Bei jeder dieser Möglichkeiten kann
man zwischen vorzeichenlosen und vorzeichenbehafteten Integer-Werten wählen.
Neben diesen zu erwartenden Möglichkeiten, besteht auch die Möglichkeit
4 32-Bit-Fließkommazahlen in einem Vektor unterzubringen. Die Vektor-ALU
beherrscht also sowohl Integer- als auch FP-Operationen, wodurch sich erahnen
läßt, woher der beachtliche Platzbedarf der Einheit rührt
(siehe links oben auf dem G4 Die). Außerdem wird deutlich, worin
sich die enorme Anzahl neuer Befehle begründet: Viele Befehle unterscheiden
sich nur im verwendeten Datentypen voneinander.
Wie bereits erwähnt unterteil sich die Vektor-Einheit logisch in
eine Vektor-ALU und eine Permutationseinheit. Die Vektor-ALU ist für
die tatsächlichen Berechnungen nach den SIMD-Prinzip (single instruction
multiple data) zuständig. Die Permutationseinheit wird benötigt,
um die Elemente innerhalb der Vektoren anzuordnen. Wurde etwa in einem
Vektor der 16 Elemente enthält für je vier benachbarte Elemente
das Minimum bestimmt, so entsteht ein Ergebnisvektor, der nur an vier Positionen
brauchbare Daten enthält (die vier Minima), die restlichen 4x3 Felder
sind leer. Wurde diese Operation auf 4 Vektoren ausgeführt so lassen
sich die 4x4 Ergebnisse zu einen neuen Vektor zusammenfügen ("kompaktieren"),
um damit weiterzurechnen.
 Im
ersten Beispiel wir das Skalarprodukt von 16-elementigen Vektoren berechnen.
Die Vektoren werden komponentenweise miteinander multipliziert, die Produkte
werden aufsummiert. In die Summe fließt zusätzlich der Ergebnisvektor
einer vorhergehenden Berechnung ein. Der gesamte Vorgang umfaßt mit
dem bisherigen PowerPC Befehlssatz 36 Befehle, die sich auf nur noch 2
AltiVec-Befehle reduzieren.
Im
ersten Beispiel wir das Skalarprodukt von 16-elementigen Vektoren berechnen.
Die Vektoren werden komponentenweise miteinander multipliziert, die Produkte
werden aufsummiert. In die Summe fließt zusätzlich der Ergebnisvektor
einer vorhergehenden Berechnung ein. Der gesamte Vorgang umfaßt mit
dem bisherigen PowerPC Befehlssatz 36 Befehle, die sich auf nur noch 2
AltiVec-Befehle reduzieren.
Das zweite Beispiel (erstes Bild unten) veranschaulicht, wie durch neue Befehle ganze Kontrollflußsequenzen eingespart werden. Die Sequenz
for (i=0; i<16; i++) { // 16 8-Bit-Elemente
if (a[i]==b[i]) // die oberen beiden Vektoren
r[i]=x[i]; // x: erste Quelle
else
r[i]=y[i]; // y: alternative Quelle
} // r: Ergebnis (unten)
läßt sich durch zwei Vektor-Befehle ausdrücken: Zunächst
werden die beiden Vektoren a und b miteinander verglichen und eine Ergebnismaske
berechnet, die an der Stelle i eine 0 enthält, wenn die beiden Elemente
a[i] und b[i] unterschiedlich waren, sonst den Wert FF. Dann wird mit dem
vsel-Befehl (Vector select) der Ergebnisvektor abhängig von der berechneten
Maske aus den beiden Quellvektoren x und y zusammengestellt (-> Permutationseinheit).
Wiederum wird eine vorher 48 Befehle lange Sequenz auf 2 Vektor-Befehle
reduziert.
 Das
dritte Beispiel bezieht sich auf einen weiteren wesentlichen Bereich des
neuen Befehlssatzes, das Datenmanagement. In den genannten Einsatzgebieten
um Audio- und Videobearbeitung wird extensiv mit Datenströmen gearbeitet.
Dabei wirken sich herkömmliche Caching-Mechnismen oft ungünstig
aus, so daß der erweiterte Befehlsatz zahlreiche Möglichkeit
zu Beeinflussung des Speichermanagements bietet. Aus dem Quelltext heraus
läßt sich etwa ein Prefetch von bis zu vier Datenströmen
in den Cache veranlassen. Darüber hinaus können Daten "aufgehoben"
werden, d.h. das Überschreiben im Cache kann verhindert werden, wenn
die Daten in Kürze erneut benötigt werden. Eine solche Beeinflussung
war bisher nicht möglich und kann ggf. viel Zeit sparen.
Das
dritte Beispiel bezieht sich auf einen weiteren wesentlichen Bereich des
neuen Befehlssatzes, das Datenmanagement. In den genannten Einsatzgebieten
um Audio- und Videobearbeitung wird extensiv mit Datenströmen gearbeitet.
Dabei wirken sich herkömmliche Caching-Mechnismen oft ungünstig
aus, so daß der erweiterte Befehlsatz zahlreiche Möglichkeit
zu Beeinflussung des Speichermanagements bietet. Aus dem Quelltext heraus
läßt sich etwa ein Prefetch von bis zu vier Datenströmen
in den Cache veranlassen. Darüber hinaus können Daten "aufgehoben"
werden, d.h. das Überschreiben im Cache kann verhindert werden, wenn
die Daten in Kürze erneut benötigt werden. Eine solche Beeinflussung
war bisher nicht möglich und kann ggf. viel Zeit sparen.
Das vierte Beispiel zeigt eine weitere Funktion der Permutationseinheit.
Ähnlich der im zweiten Beispiel berechneten Maske für die Elementauswahl
lassen sich auch die Positionen der gesuchten Elemente in den Quellvektoren
angeben. Ensprechende wird dann der Ergebnisvektor aus den beiden Quellvektoren
"zusammengesammelt", was wiederum ohne einen speziellen Befehl ein vielfaches
der Zeit in Anspruch nehmen würde.