PowerPC MPC750
Einleitung
Architektur
Instruction Unit
Branch-Processing-Unit (BPU)
Completion-Unit
Execution-Unit
Memory-Management-Unit (MMU)
Cache
Bus-Interface-Unit
Pipeline
Power-Saving-Modi, Temperaturmanagement
Einleitung
Die Architektur des PowerPC soll anhand des MPC750 erläutert werden.
Der MPC750 ist ein RISC-Computer (Reduced Instruction Set Computer),
verwendet also einen kleinen Befehlssatz einfacher Befehle mit kurzer Ausführungszeit.
Er ist in 32-Bit-Architektur ausgelegt, mit 32-Bit effektiven Adressen
und 32 bzw. 64-Bit Datenbus.
Der MPC750 kann als superskalarer Prozessor
bezeichnet werden, da abgesehen von der gleichzeitigen Bearbeitung der
Befehle in der Pipeline wirklich zwei Befehle gleichzeitig an die Execution-Units
weitergegeben werden können.
Der MPC750 ist schnell. So verwendet er z.B. eine in 3 Stufen gepipelinete
Floatingpoint-Unit und die meisten Integer-Befehle brauchen nur einen Takt.
Es gibt neben den getrennten L1-Caches für Befehle und Daten eine
L2-Cache-Verwaltung (incl. Tag-Memory) auf dem Chip.
Der MPC750 ist in CMOS-Technologie gefertigt.
Architektur
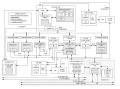
Der Prozessor besteht aus:
-
Instruction Unit
Entscheidet, welcher Befehl als nächstes bearbeitet werden soll,
ob z.B. sequentiell der nächste Befehl genommen werden soll oder ob
gesprungen wird, und leitet ihn an die entsprechende Execution-Unit weiter.
-
6 Execution-Units
Führen den Befehl aus, z.B. eine arithmetische Berechnung, eine
Sprungzielberechnung oder ein Speicherzugriff.
-
Registereinheiten für Floatingpointzahlen (FPR)
und und Daten in Festkommadarstellung (GPR-general purpose
register)
-
getrennte Daten- und Befehlscaches
Speichern Blöcke von Daten bzw. Befehlen, damit nicht zu häufig
auf den Hauptspeicher zugegriffen werden muß.
-
Data/Instruction MMU (Memory-Management-Unit)
Kontrolliert den Cache-Zugriff
-
Completion-Unit
Reorganisiert die richtige Befehlsfolge bei falsch vorhergesagtem Sprung
oder bei Exceptions.
-
Bus-Interface-Unit
Kontrolliert den Bus
Instruction Unit
Die Instruction-Unit steuert zentral die Abfolge der abzuarbeitenden Befehle
und den Befehlsfluß zu den Execution-Units.
Der sequentielle Fetcher holt sequentiell
Befehle aus dem Instruction-Cache. Dazu gibt er die
in der Instruction-Unit berechnete Adresse des zu holenden Befehls an die
Instruction-Management-Unit
(Instruction MMU), welche ihrerseits den Instruction-Cache veranlaßt,
bis zu 4 Befehle, genauer soviel, wie freie Pläzte in der Queue sind,
gleichzeitig ('gleichzeitig' heißt in diesem Zusammmenhang 'innerhalb
eines Takts') in die Instruction-Queue in der Instruction-Unit zu leiten.
Außerdem meldet der Fetcher den Befehl an die Completion-Unit,
da eine vorhergesagte und daher in Ausführung gegebene sequentielle
Befehlsfolge falsch sein kann. Die aus dem Instruction-Cache gefetchten
Befehle werden in der als Zwischenspeicher dienenden Instruction-Queue
abgelegt, welche Platz für 6 Befehle hat.
Um Sprünge ausrechnen und die benötigten Befehle fetchen
zu können, ist in der Instruction-Unit die Branch-Processing-Unit
(BPU) eingebaut. Wenn ein Sprung vorhergesagt ist, meldet die BPU die Befehlsadresse
an den Fetcher, der an dieser neuen Stelle sequentiell fortfährt.
Von den unteren Plätzen der Instruction-Queue gelangen die Befehle
in die Dispatch-Unit, welche jeweils 2 Befehle gleichzeitig (->superskalarer
Prozessor) an die Execution-Units leiten kann. Gleichzeitig werden diese
Befehle auch an die Completion-Unit weitergegeben.
Die Dispatch-Unit prüft auf Datenabhängigkeiten
in Quell- und Zielregister.
Branch-Processing-Unit (BPU)
Die Branch-Processing-Unit (BPU) erhält alle Sprungbefehle aus dem
Fetcher, wertet diese aus, errechnet Sprungziele und updatet den Programmcounter
(Countregister-CTR). Die Berechnung, ob ein Bedingter-Sprung genommen werden
muß oder nicht, dauert einen Takt, was zu einem Loch in der zeitlichen
Befehlsabfolge führen müßte, weil der auf den Sprung folgende
Befehl noch nicht bekannt ist. Daher ist es sinnvoll, in geeigneter Weise
den Sprung vorherzusagen, um ohne Verzögerungen von einem Takt im
Programm fortfahren zu können. Im Falle einer falschen Vorhersage
müssen allerdings die Wirkungen aller auf den Sprung folgenden Befehle
rückgängig gemacht werden und im korrekten Befehlspfad weitergearbeitet
werden.
Es gibt zwei Arten von Sprungvorhersagen (branch prediction), statische
und dynamische. Für die statische Sprungvorhersage wird ein
(64-entry, 16-set, 4-way-set-associativ ) Branch-Target-Instruction-Cache
(BTIC) mit den Sprungzielen der letzten Befehle im Programmablauf verwendet.
Für die dynamische Sprungvorhersage wird ein (512-entry) Branch-History-Table
(BHT) verwendet, welcher in 2 Bits die Wahrscheinlichkeit eines Sprungs
für die letzten Befehle speichert. Diese Wahrscheinlichkeiten werden
je nach Ergebnis des tatsächlichen Sprungverhaltens geupdatet und
sagen aus, ob ein Sprung 'unwahrscheinlich', 'höchst unwahrscheinlich',
'wahrscheinlich' oder 'höchst wahrscheinlich' ist. So wird in den
meisten Fällen nur ein Takt pro Sprungbefehl benötigt.
Completion-Unit
Die Completion-Unit arbeitet eng mit der Instruction-Unit
zusammen. Befehle werden in der Instruction-Unit in sequentieller Folge
gefetcht und dispatched, und zwar in der Reihenfolge, wie sie durch den
Programmlauf vorgegeben ist. Nach Aufteilung der Befehle an die Execution-Units
muß diese Reihenfolge irgendwo gespeichert werden. Denn, falls bei
einem falsch vorhergesagtem Sprung oder bei einer Exception einige Befehle,
die sich bereits in den Execution-Units befinden, nicht ausgeführt
werden dürfen, so darf ihr Resultat nicht endgültig in die Register
geschrieben werden. Daher wird jeder dispatchte Befehl in Reihenfolge in
den (6-entry) Reorder-Buffer, einer Queue in der Completion-Unit,
geschrieben. Dort ist Platz für 6 Befehle, denn es können maximal
6 Befehle gleichzeitig in den 6 Execution-Units behandelt werden. Entsprechend
kann ein Befehl erst dispatched werden, wenn wieder Platz in der Queue
ist. Wenn ein Befehl in einer Execution-Unit
fertig ausgeführt ist, wird das Resultat der Berechnung in ein Register
(GPR, FPR, CTR) geschrieben, und zwar in der Reihenfolge, wie sie in der
Reorder-Buffer-Queue steht. Wird ein Befehl wegen falscher Sprungvorhersage
oder einer Exception zurückgezogen, so wird er aus der Queue gestrichen.
Dies kann passieren, solange er noch in der Queue steht. Entsprechend muß
auch das Resultat der Execution-Unit ggfs. wieder gestrichen werden. Daher
werden diese Resultate in den Registern zunächst in entsprechende Rename-Buffer
mit 6 Einträgen geschrieben, entsprechend dem Reorder-Buffer der Completion-Unit.
Erst wenn keine Gefahr für einen Befehl mehr besteht, annuliert zu
werden, er fertig ausgeführt ist und keine Exceptions stattfanden,
wird er von den unteren Plätzen der Queue in der Completion-Unit gestrichen
und das entsprechende Resultat aus dem Rename-Buffer in das Register übernommen
(und zwar maximal 2 Befehle entsprechend den 2 dispatchten Befehlen pro
Takt).
Execution-Unit
Neben der Branch-Processing-Unit gibt es 5 unabhägige Execution-Units.
-
Zwei Integer-Units
Diese führen die Integer-Berechnungen aus. Jede Unit besitzt eine Reservation-Station
mit einem Eintrag für einen Befehl aus der Dispatch-Unit und Operanden
aus dem entsprechenden Register (GPR) bzw. dem
Rename-Buffer zur Zwischenspeicherung, falls die entsprechende Unit noch
besetzt ist. Resultate werden zunächst in den Rename-Buffer geschrieben
und gelangen später in das Register,
welches 32 Einträge hat.
Jede Integer-Unit besitzt einen schnellen Addierer, eine Einheit für
logische Operationen und eine für Shifts. Jede dieser Berechnungen
dauert einen Takt. Integer-Unit-2 hat zusätzlich noch einen Multiplizierer/Dividierer,
der oft nur einen Takt braucht.
-
Eine Floating-Point-Unit
Diese führt FP-Berechnungen aus und besitzt ebenfalls eine Reservation-Station
mit einem Eintrag für einen Befehl aus der Dispatch-Unit zur Zwischenspeicherung,
falls die Unit noch besetzt ist. Operationen in Einfacher-FP-Genauigkeit
brauchen einen Durchlauf und drei Takte. Die Operanden stammen aus dem
FP-Register (FPR) bzw. dem entsprechenden Rename-Buffer,
die Resultate werden zunächst in den Rename-Buffer geschrieben und
gelangen später in das Register, welches 32 Einträge in 64-Bit
Genauigkeit hat. Die FP-Unit ist in 3 Stufen gepipelinet, so daß
in jedem Takt ein Befehl hinzugefügt werden kann, welcher 3 Takte
zur Berechnung braucht.
-
Eine System-Register-Unit
Die System-Register-Unit führt Befehle auf Sstemebene aus wie
Moves, etc und hat eine Reservation-Station mit einem Eintrag für
einen Befehl aus der Dispatch-Unit zur Zwischenspeicherung.
-
Eine Load/Store-Unit (LSU)
Die Load/Store-Unit führt alle Lade- und Speicherbefehle aus,
hat Verbindung zu den Registern und dem Cache-Hauptspeicher-System
und berechnet effektive Speicheradressen. Sie besitzt ebenfalls eine Reservation-Station
mit einem Eintrag für zwei Befehle aus der Dispatch-Unit zur Zwischenspeicherung.
Wenn keine Datenabhängigkeiten bestehen, kann pro Takt eine Ladeoperation
gestartet werden, die bei einem Treffer im Cache zwei Takte braucht. Die
LSU hat also eine 2-stufige Pipeline. Die Daten werden zunächst im
entsprechenden Rename-Buffer des Registers
gespeichert. Das Speichern im Cache-Hauptspeicher-System darf nicht sofort
geschehen, falls ein Speicherbefehl annuliert wird. Daher werden die Daten
zunächst in einer Store-Queue mit 3 Einträgen abgelegt, bis die
Completion-Unit
ihr OK signalisiert. Es kann ein Speicherbefehl pro Takt ausgeführt
werden, der drei Takte braucht, um die Daten im Cache zu speichern. Die
wirklichen durchschnittlichen Lade- und Speicherzeiten hängen vom
Prozessor-Bus-Takt ab und davon, ob der L2-Cache oder gar der Hauptspeicher
mit beteiligt sind.
Memory-Management-Unit (MMU)
Es gibt jeweils eine MMU für Daten und eine für Befehle entsprechend
den getrennten L1-Caches. Die MMU unterstützt
252 virtuelle und 232 physikalische Adressen für
Daten und Befehle und kontrolliert den Daten- bzw. Befehlsfluß zwischen
Load-/Store-Unit bzw. Instruction-Unit und den L1-Caches. Dazu übersetzt
die MMU die in der Instruction- bzw. Load-/Store-Unit berechneten effektive
Adressen in die physikalischen für den Speicherzugriff. Dabei können
Seiten von 4-Kbyte oder Blöcke von 128-Kbyte bis 256-Mbyte verwendet
werden. Im optionalen Real-addressing-mode ist die Übersetzung abgeschaltet,
effektive sind dann gleich physikalischen Adressen.
Die Interaktion zwischen Cache und Hauptspeicher kann nach dem Write-Back
oder der Write-Through Prinzip gewählt werden. Der Cache kann auch
abgeschaltet werden, und der Speicherzugriff kann auf einzelnen Befehlen,
block- oder seitenweise geschehen.
Die übersetzten physikalischen Adressen werden zusammen mit ihren
effektiven im Pagetable (block-address-translation-buffer, DBAT
bzw. IBAT) gespeichert. Für einen schnellen Zugriff gibt es für
beide Pagetable eine Art Cache (128-entry, 2-way-set-associativ, LRU-replacement-algorithmus),
den Translation-Lookaside-Buffer (TLB) zu dieser
Tabelle (DTLB bzw ITLB) für die zuletzt gebrauchten Adressen. Die
Suche im Pagetable ist in Hardware implementiert.
Cache
Zugriffe auf den Hauptspeicher dauern einige Zeit. Daher ist es sinnvoll,
einen schnellen Zwischenspeicher (Cache) für die am häufigsten
benötigten Daten/Befehle zwischen Prozessor und Hauptspeicher auf
den Chip zu setzen.
Auf dem MPC750 befinden sich für Daten und Befehle getrennte L1-Caches,
sowie ein L2-Cache-Interface.
L1-Caches
Der Befehls- und der Datencache sind jeweils 32 kByte groß und mengenassoziativ
mit 8 Einträgen/Blöcken pro Index (d.h. pro Menge) (8-way-set-associative).
Die Indices und Tags beziehen sich auf die physikalischen Adressen der
Einträge.
Jeder Eintrag besteht aus dem Adressen-Tag (das sind die Adressenbits
ohne dem Index), einem Zustandsbit und 8 aufeinander folgenden Worten (also
einem 32 Byte, 8-Wort Block). Als erstes Wort ist jeweils nur jedes achte
zugelassen, so daß die 8-Wort-Blöcke sich nie überschneiden.
Die Bits 27-31 sind somit für die Adressierung dieser 8 Worte und
ihrer 4 Bytes vorgesehen. Es ergeben sich demnach (wegen der 32 kByte)
128 Mengen (128Mengen*8Blöcke*8Wörter*4Byte<Wortlänge>
= 32 kByte).

Um ein Wort/Befehl im Cache zu finden, stellt man mit den ersten 7 Bits
der physikalischen Adresse die Menge fest, in der sich das Wort befinden
muß (die Menge ist direkt adressiert). Dann überprüft man
für jeden der 8 Blöcke, ob Bit 7-26 dem eingetragenen Tag entspricht.
Falls nein, so ist das Wort nicht enthalten, falls ja, so kann man mit
den Bits 27-29 das Wort unter den 8 eingetragenen identifizieren.
Um ein Wort im Cache einzutragen, ermittelt man wie oben die Zielmenge
und trägt den dieses Wort umfassenden 8er-Block in einen noch freien
Block ein oder überschreibt einen nach einem Least-Recently-Used-Replacement-Algorithmus
zu ermittelnden Block. Dabei geht man davon aus, daß die am längsten
nicht benötigten Daten/Befehle im Cache am unwahrscheinlichsten benötigt
werden und sie daher überschrieben werden können. Der L1-Cache
arbeitet wahlweise mit dem Write-Back- oder Write-Through-Verfahren. Es
können 2 Worte bzw. 4 Befehle pro Takt aus dem Cache gelesen werden.
Der Cache kann softwareseitig abgeschaltet oder gesperrt werden.
Desweiteren seien der Branch-Target-Instruction-Cache
in der Branch-Unit und die TLBs als weitere Caches erwähnt
(s.o.).
L2-Cache-Interface
Neben den L1-Caches ist ein weiterer L2-Cache zwischen L1-Cache und Hauptspeicher
vorgesehen. Dieser umfaßt Daten wie Befehle gleichermaßen und
empfängt Anforderungen von den L1-Caches. Auf dem Chip ist allerdings
nur eine Kontrolleinheit und ein mengenassoziativer Speicher (mit 2 Einträgen
pro Index) für 2*4k Tags vorhanden. Die Daten werden in externen
SRAMs variabler Größe (256 kByte bis 1MByte) gespeichert. Anfragen
vom L1-Cache resultieren, wenn Daten/Befehle dort nicht vorhanden sind
oder bei Write-Through-Operationen, d.h. dem Updaten des übergeordneten
Speichers mit den Daten des L1-Caches. Die Anfragen werden mit den Tags
des L2-Caches verglichen. Falls kein Treffer vorliegt, wird die Anfrage
an die Bus-Interface-Unit weitergeleitet. Der L2-Cache arbeitet mit
dem Write-Back-Verfahren.
Bus-Interface-Unit
Es gibt jeweils eine Bus-Interface-Unit als Schnittstelle zum Speicher
des L2-Caches und zum Hauptspeicher mit einem 32 Bit Adressbus und 64 Bit
Datenbus zum Hauptspeicher und einem 17 Bit Adressbus und 64 Bit Datenbus
zum L2-Cache-Datenspeicher.
Pipeline
Der MPC750 ist ein gepipelineter superskalarer Prozessor. Eine Pipeline
teilt die Ausführung der Befehle in mehrere Stufen auf, so daß
innerhalb eines Taktes an mehreren Befehlen gleichzeitig gearbeitet werden
kann, die ungenutzten Abarbeitungsstufen eines Befehls in einem Takt also
für andere Befehle genutzt werden können. Z.B. kann Befehl Y
schon gefetcht werden, während Befehl X in einer Execution-Unit bearbeitet
wird.
Bei einem superskalaren Prozessor werden mehrere Befehle gleichzeitig
in verschiedenen Execution-Units bearbeitet. Die Pipeline alleine würde
nur eine Execution-Unit innerhalb eines Taktes versorgen, die anderen lägen
brach. Superskalarität nutzt mehrere Execution-Units gleichzeitig.
Um den Zeitgewinn auch wirklich nutzen zu können, können 4 Befehle
innerhalb eines Taktes aus dem Instruction-Cache gefetcht werden und 2
dispatchet werden. (Ein Teil der Befehle wird in der BPU dazwischen verarbeitet.)
Das ganze wird mit erhöhtem Verwaltungsaufwand erkauft (getrennte
Register für Integer- und FP-Daten).
Die Pipeline des MPC750 hat 4 Stufen, durch die alle Befehle gehen
müssen:
-
Fetch (realisiert durch Fetcher)
Erhält Befehle vom Speichersystem und bestimmt die Adresse des
nächsten Befehls. Arbeitet mit BPU zusammen.
-
Decode/Dispatch (realisiert durch Dispatch-Unit)
Dekodiert den Befehl und steuert die Datenkonfliktfreie Weitergabe
an die Execution-Units. Wenn die Operanden für einen Befehl in den
GPR/FPR-Registern oder den zugehörigen Rename-Buffern
erhältlich sind, werden sie ausgelesen und in die Execution-Phase
weitergeleitet. Ansonsten erhält der Befehl einen Tag, welcher das
Rename-Register angibt, in dem der Operand enthalten sein wird, sobald
er erhältlich ist. Am Ende der Dispatch-Phase sind der Befehl und
seine Operanden an eine Execution-Unit weitergegeben.
Zusammen mit einem Befehl für die Branch-Unit können 3 Befehle
innerhalb eines Taktes dispatched werden.
-
Execute (realisiert durch Execution-Units)
Führt die Berechnung des Befehls aus und schreibt das Ergebnis
in den entsprechenden Rename-Buffer.
-
Complete/Write-Back (realisiert durch GPR/FPR-Files,
Completion-Unit)
Erhält den korrekten Zustand in der Abfolge der Befehle und überträgt
die Ergebnisse aus den Rename-Registern in die GPR/FPR-Register.
Die FP-Unit hat wiederum 3 Pipelinestufen: Multiplizieren, Addieren, Runden.
Die Load/Store-Unit hat 2 Stufen: Berechnung der effektiven Adresse incl.
Übersetzung in Physikalische Adresse, Zugriff der Daten im Cache.

Zwischen den Pipelinestufen muß es Register zum Zwischenspeichern
der Resultate einer Stufe geben. Es sind dies
Diese Register reduzieren Stalls und sind desweiteren in Zusammenhang mit
der Sprungvorhersage wichtig.
Power-Saving-Modi, Temperaturmanagement
Der MPC750 kennt vier verschiedene Power-Saving-Modi. Damit können
vorübergehend nicht benötigte Einheiten in einen geeigneten Energiesparmodus
gesetzt werden ohne die Performance negativ zu beeinflussen (Dynamic-Power-Management)
oder Einheiten teilweise abgeschaltet werden (Doze, Nap, Sleep), wobei
je nach Deaktivierungsgrad nur wenige Takte benötigt werden, um den
Prozessor in den Full-Power-Modus zu überführen.
Es gibt eine Temperaturüberwachung und Temperaturmanagement, nützlich
für portable Computer mit kleinen Abmessungen. Die Temperatur wird
geregelt, indem die Systemgeschwindigkeit verändert oder Operationen
vorübergehend gestoppt werden.
Die Instruction-Fetch-Rate kann geregelt werden, um die Energieaufnahme
zu begrenzen (z.B. bei Embedded-Systems).
(The images are taken from the Motorola Website. If anyone
there should be bothered about finding them here, please mail.)
zum Inhalt