Compositional data is a special type of of non-negative data, which carries the relevant information in the ratios between the variables rather than in the actual data values. The individual parts of the composition are called components or parts. Each component has an amount, representing its importance within the whole. The sum over the amounts of all components is called the total amount, and portions are the individual amounts divided by this total amount (van den Boogaart and Tolosana-Delgado 2013).
The great challenge of compositional data is that no single component can be regarded as independent from other. This means, if you observe a (e.g. spatial or temporal) pattern within one single component, at least parts of the pattern is likely rather attributed to another part of the composition than the (spatial or temporal) behaviour of the varibale of interest it self.
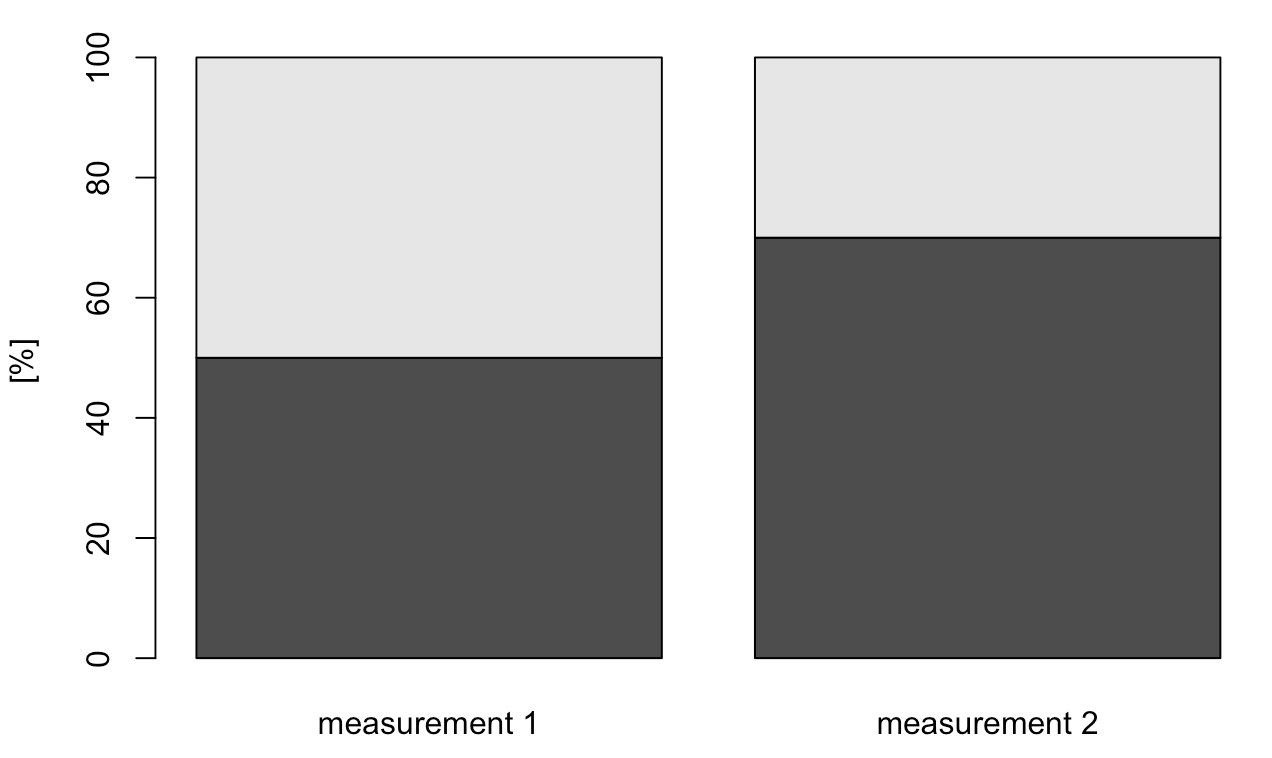
A simple example:¶
Imagine two measurements of a 2-part composition which sum up to a whole: