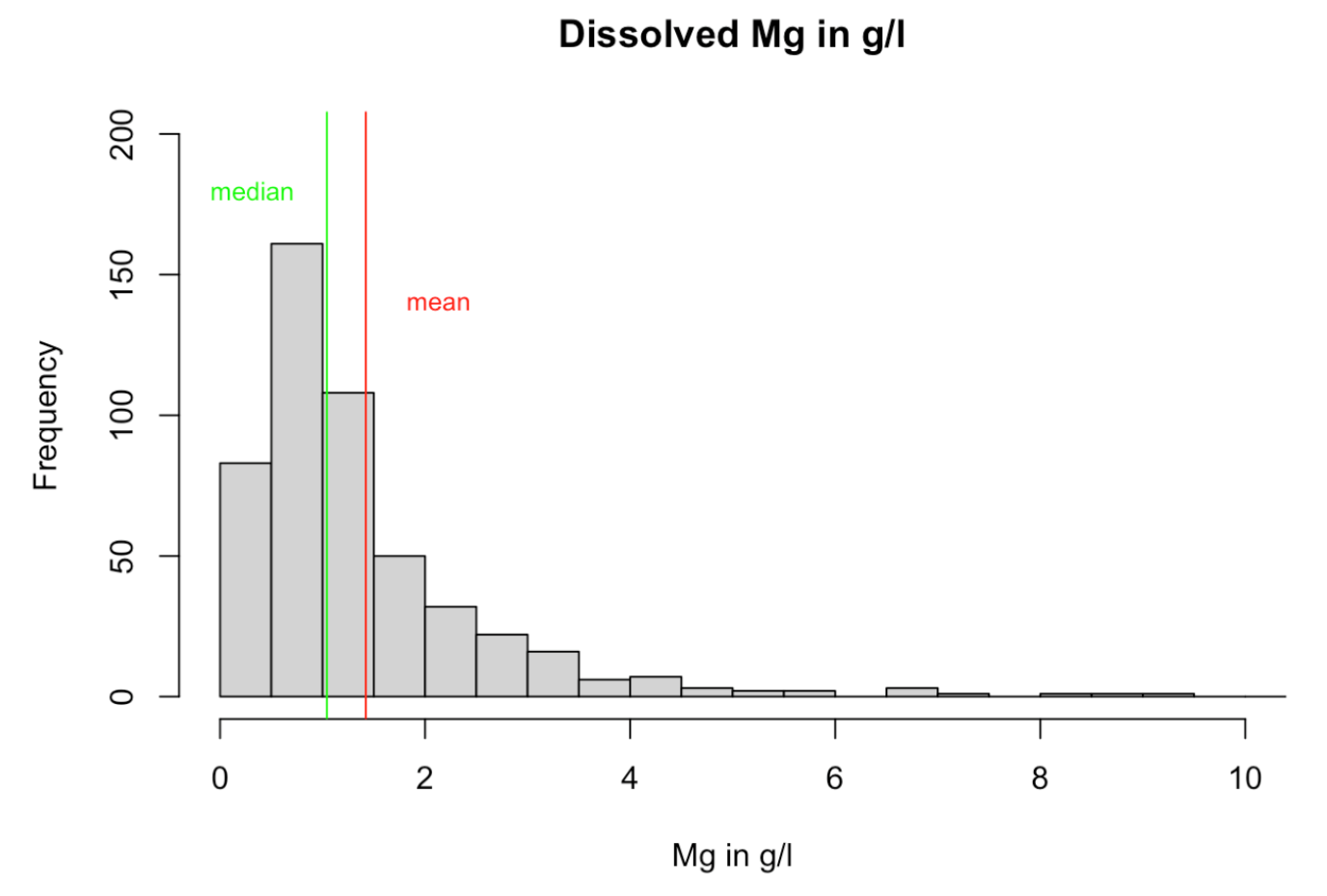
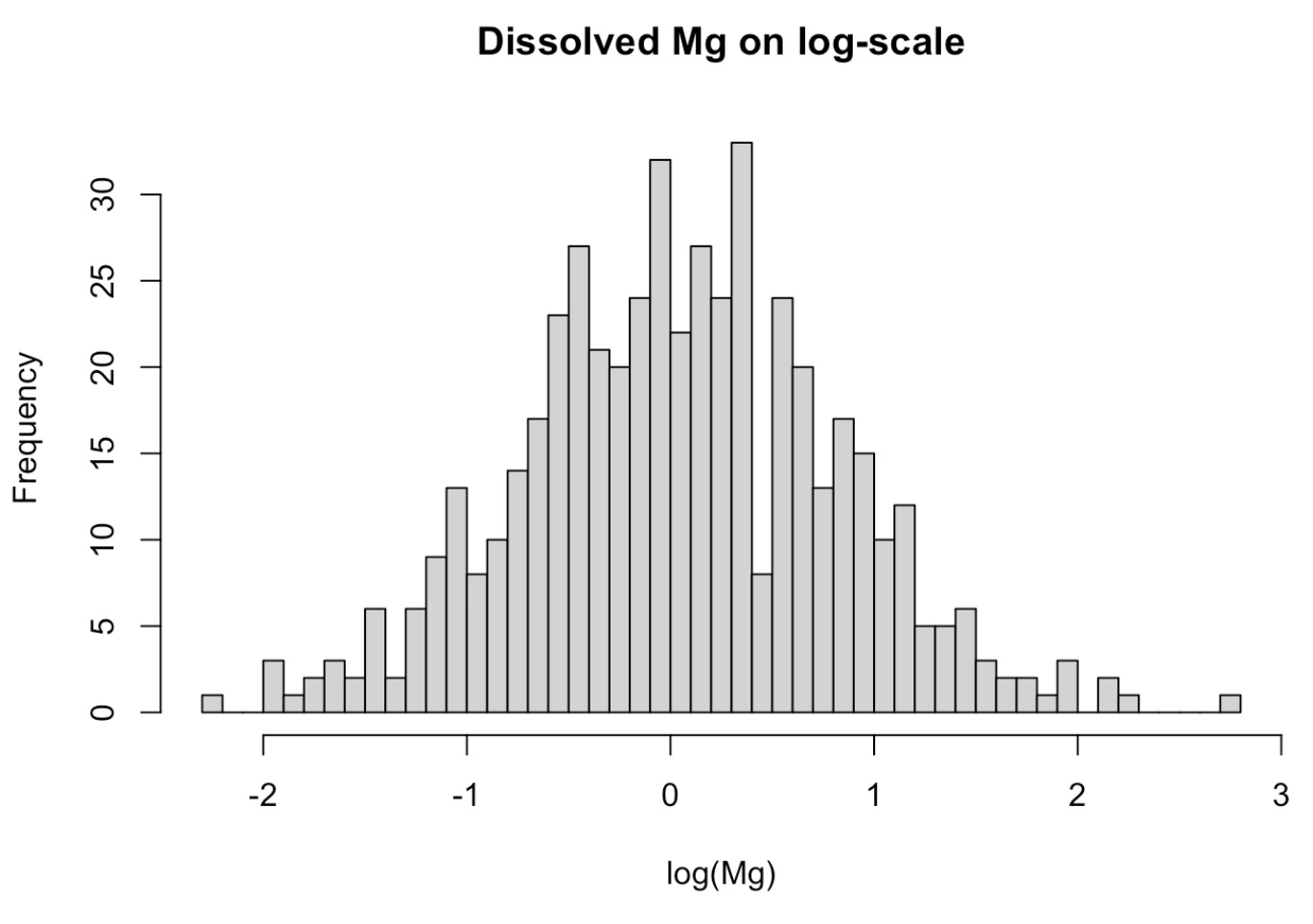
*A simple example:*
Let us generate a 3-part random composition by defining 2 random variables and a remainder to the total.
All three parts should be independent.
|
A |
B |
C |
| Min. |
0.4925 |
0.4783 |
40.63 |
| 1st Qu. |
7.9098 |
11.8154 |
52.27 |
| Median |
21.3940 |
17.6066 |
62.03 |
| Arithm. mean |
18.4264 |
17.9454 |
63.63 |
| 3rd Qu. |
27.4527 |
25.2677 |
75.83 |
| Max |
31.5422 |
32.4978 |
86.17 |
All three parts should be independent.
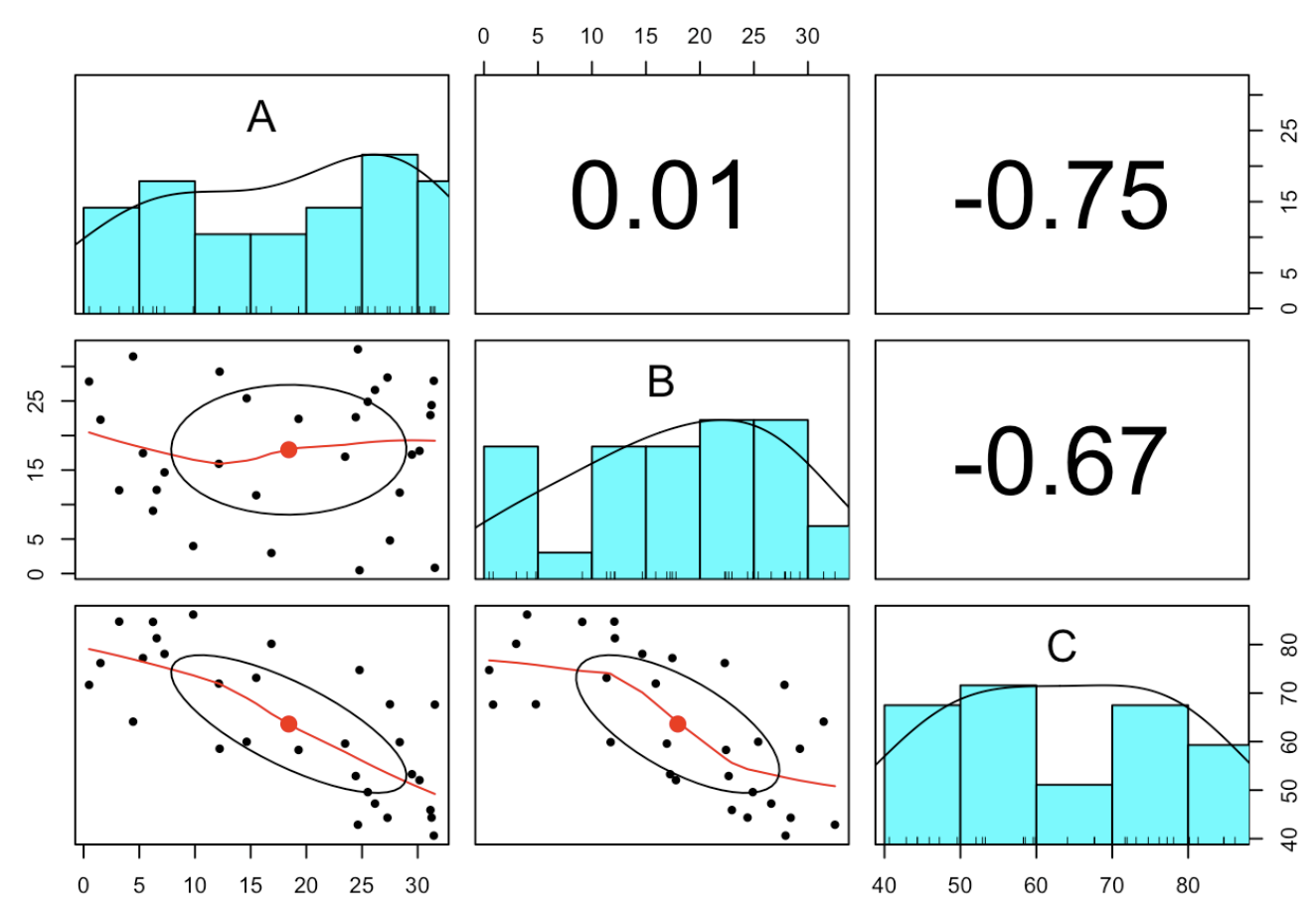
As we see, both random variables are correlated with the remainder. Imagine, we are measuring another part and extent the composition by variable D. Hereby, we re-generate C as random and close all 4 parts to 100%:
If closing a set of independent uniform random variable to 100%, none of them stay uniform anymore. They are loosing any symmetry and possible initial normality!
Furthermore, beside A and B all correlations are negative again.
Testing for significance of the Pearson correlation coefficient leads to the following result:
50% of possible pairs of random variable are showing up with significance correlation!
What does this imply beside obvious spurious correlations?
We can interpret the correlation coefficient as normalized cosine of the angle between the deviation vectors to the mean
$$\mathbf{x}_{d}=(x_i-\bar{x},i=1,\cdots,n)$$
and
$$ \mathbf{y}_{d}=(y_i-\bar{y},i=1,\cdots,n)$$
The cosine of the angle between two vectors is calculated by the scalar product divided to the product of both norm:
$$\cos \measuredangle (\mathbf{x}, \mathbf{y})=\frac{<\mathbf{x}, \mathbf{y}>}{\parallel \mathbf{x} \parallel \cdot \parallel \mathbf{y} \parallel }= \frac {\sum{x_i\cdot y_i }}{\sqrt{x_i^2}\cdot \sqrt{y_i^2}} $$
Setting $\mathbf{x} =\mathbf{x}-\overline{\mathbf{x}}$ and $\mathbf{y} =\mathbf{y}-\overline{\mathbf{y}}$, we are getting the scalar product as nominator for the covariance term and the product of the norms as standard deviation terms.
Thus, in compositions the deviations vectors as bases are oblique by nature and consequently non-euclidean!
Hence, statistical methods using distances and angles (ratios) as optimization parameters can not be applied on pure compositions.
Such methods are e.g.:
- (ML-)regression and correlation, GLM, PCA, LDA, ANN
- SVM, KNN, k-Means
- most hypotheses tests, etc.
Whereas, this problem is well known since Karl Pearson published the problem of spurious correlation in compositional data 1897 more than 100 years ago Felix Chayes suggest the use of ratios instead of portions:
$$ a,b \in ]0,1[_{\mathbb{R}}\to \frac{a}{b}\in \mathbb{R_+} $$
One of the remaining disadvantage was now the question about nominator and denominator, because of the often huge difference between a/b and b/a. Another problem was still the limit to the positive reel feature scale.
In 1981, the Scottish statistician John Aitchison solved the problem introducing the log-ratios:
$$ \log \frac{a}{b}=-\log \frac{b}{a}\in\mathbb R\, .$$
Thus, changing nominator and denominator just change the sign of the log-ratio but not the absolute value implies symmetry again (cf. paragraph above)
In his Book The statistical analysis of composional data, 1986 introduced
- Additive log-ratio (alr) transformation is the logarithm of the ratio of each variable divided by a selected variable of the composition. Alr applied on a D-dimensional composition results in a D-1-dimensional variable space over the field $(\mathbb{R},+,\cdot)$. Unfortunately, beside a asymmetry in the parts, alr is not isometric. Thus, distances and angles are not consistence between simplex and the resulting D-1 dimensional subspace of $\mathbb{R}^D$.
- Centered log-ratio (clr) transformation is the logarithm of the ratio of each value divided through the geometric mean of all parts of the corresponding observation. The clr transformation is symmetric with respect to the compositional parts and keeps the same number of components as the number of parts in the composition. Due to the problem that orthogonal references in that subspace are not obtained in a straightforward manner, Egozcue et al. 2003 introduced:
- Isometric log-ratio (ilr) transformation is isometric and provides an orthonormal basis. Thus, distances and angles are independent from the sub-composition (symmetric in all parts of the sub-composition) comparable between the Aitchison simplex and the D-dimensional reel space.
However, PCA or SVD-analysis on a clr-transformed simplex provides similar properties Egozcue et al. 2003.
Double constrained feature spaces¶
There is a certain relation to the compositional constraint if we face double bounded feature spaces.
Let us imagine a variable $\mathbf{x}=(x_i\in ]l,u[_\mathbb R,i=1,\cdots,m)$ within a constrained interval [a,b]$\subset \mathbb R$. The absolute value is obviously of minor interest compared with the relative position between l and u. A first step should be a linear min-max-transformation wit min=l and max=u:
$$ x \to x' =\frac{x-l}{u-l} \in\ ]0,1[\ \in \ {\mathbb R}_+ $$
Now, x' divides the interval into two parts: 1. the distance to the left (=x) and 2. the distance to the right (1-x). Both sum up to 1 and are therefore related to a 2-dimensional composition.
Applying an alr-transformation to our variable, we are getting a symmetric feature scale:
$$ x'\to x''=\log(\frac{x'}{1-x'})\in \mathbb R$$
This so-called logistic transformation enable application of algebraic operation over the base field $\mathbb R$.
Feature scales and machine learning approaches¶
As shown above, normalization, scaling, standardization and transformations are crucial requirements for reliable and robust application of statistical methods beyond simple data description for getting meaningful results.
Especially application of complex machine learning algorithms for exploration of multivariate data patterns it often becomes likely to get entrapped for violation of important preconditions.
Hereby, it can be the violation of scale homogeneity using gradient descent related optimization technics or non-euclidean feature space for distance or angle related technics as well as simple violation of algebraic constraints.
A brief overview of common risk concerning serious pitfall is provided by Minkyung Kang in his data science blog:
ML Models sensitive to feature scale
- Algorithms that use gradient descent as an optimization technique
- Linear Regression
- Neural Networks
- Distance-based algorithms
- Support Vector Machines
- KNN
- K-means clustering
- Algorithms using directions of maximized variances
ML models not sensitive to feature scale
- Tree-based algorithms
- Decision Tree
- Random Forest
- Gradient Boosted Trees