Call:
lm(formula = Political_knowledge ~ Age, data = d)
Coefficients:
(Intercept) Age
1.4761 0.0296 (Wiederholung:) Bivariate lineare Regression
Methoden der empirischen Kommunikations- und Medienforschung
Daten der heutigen Sitzung

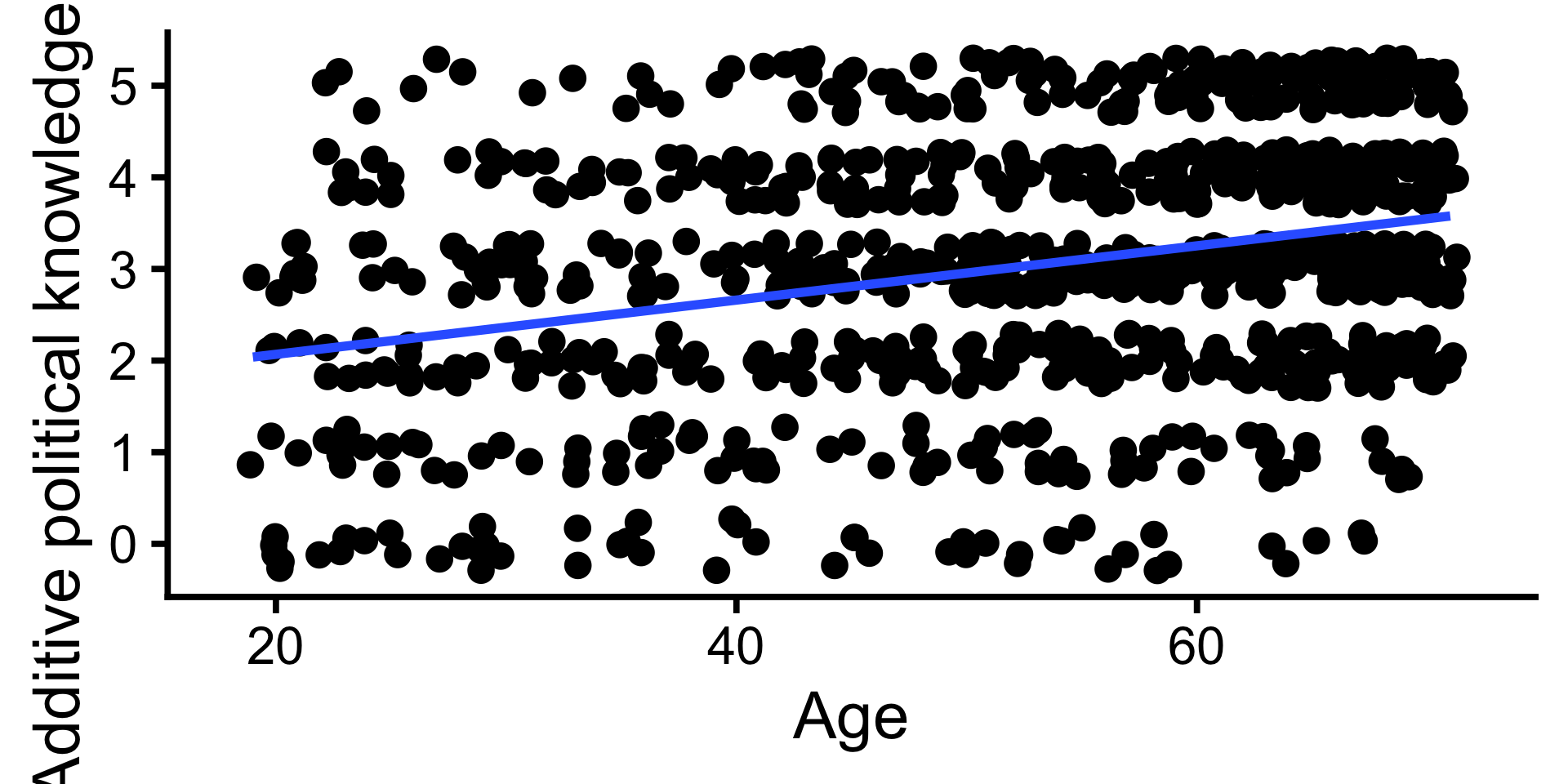
Scatterplot und Regressionsgerade

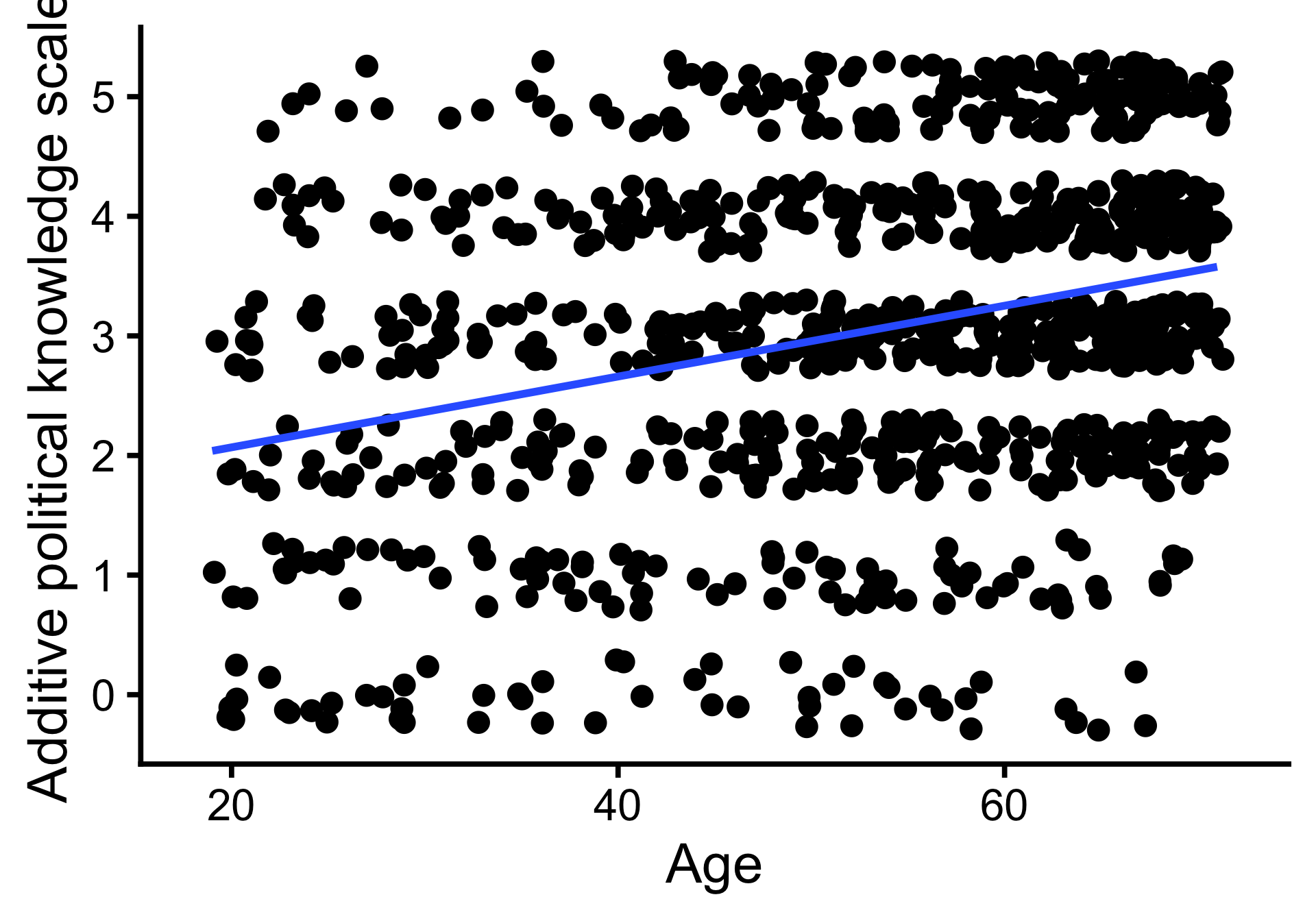
Jittered scatterplot und Regressionsgerade
Koeffizienten
Koeffizienten
- In der bivariaten Regression wird eine Gerade durch die Punkte des Streudiagramms gelegt
- Die Gerade wird durch die durch eine lineare Gleichung mit zwei Koeffizienten definiert:
- allgemein: \(y = b_0 + b_1 * x\)
- hier: \(\text{Political_knowledge} = 1.48 + 0.03 * \text{Age}\)
- Mit \(b_0\) Schnittpunkt mit Y-Achse (Konstante, Intercept) und \(b1\) Steigung der Gerade (Slope)
- \(b_0\): Wenn Age den Wert 0 hat, dann hat Political_knowledge den Wert 1.48.
- \(b_1\): Wenn Age um 1 Jahr steigt, dann steigt Political_knowledge um 0.03.
Schätzung
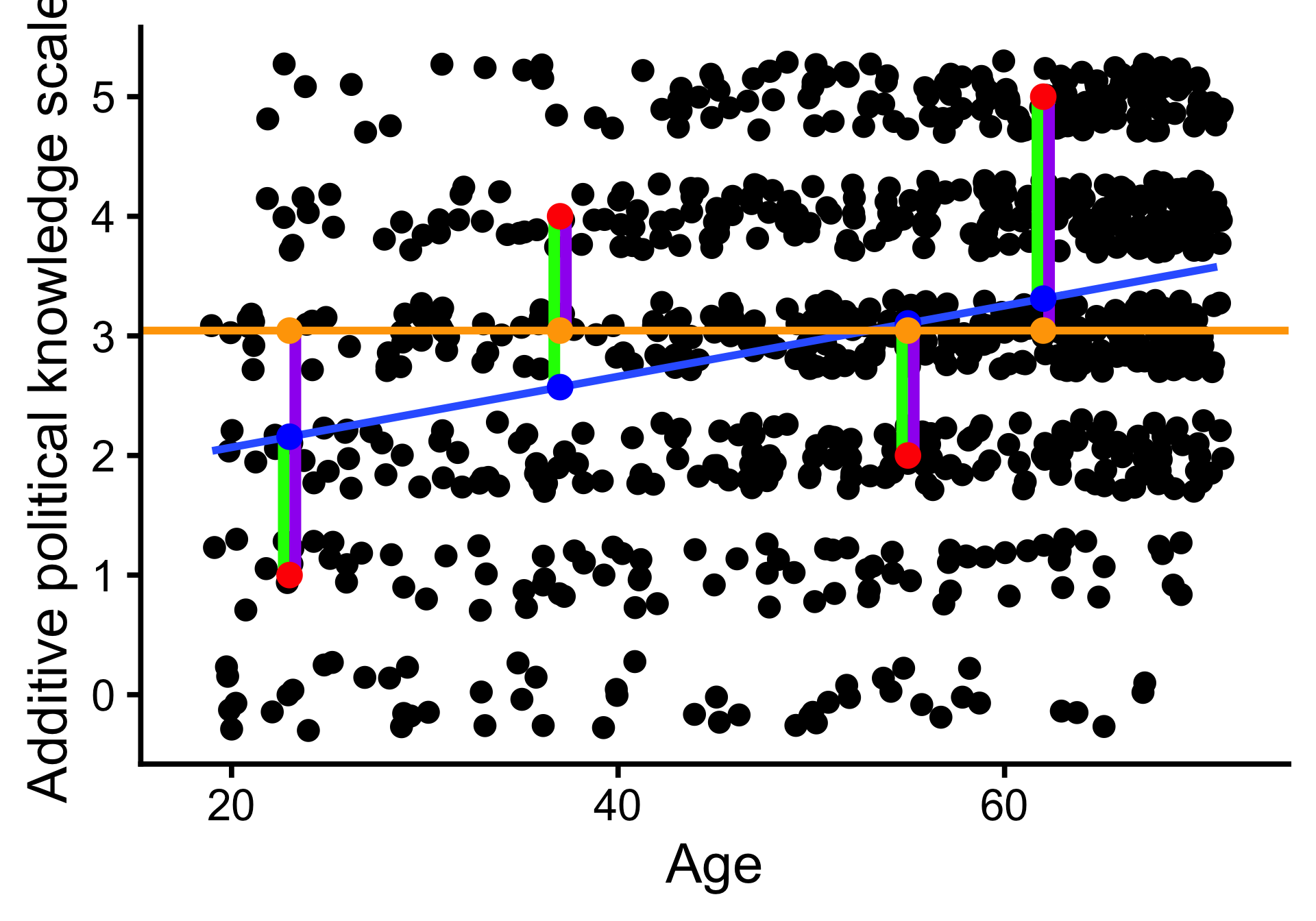
Beispiel für vier Befragte:
| Age | y | yhat | e | e2 |
|---|---|---|---|---|
| 23 | 1 | 2.16 | -1.16 | 1.34 |
| 37 | 4 | 2.57 | 1.43 | 2.04 |
| 55 | 2 | 3.10 | -1.10 | 1.22 |
| 62 | 5 | 3.31 | 1.69 | 2.85 |
- \(y\): Beobachteter Wert
- \(\hat y\): Vorhergesagter Wert
- \(e\): Residuum, Vorhersagefehler
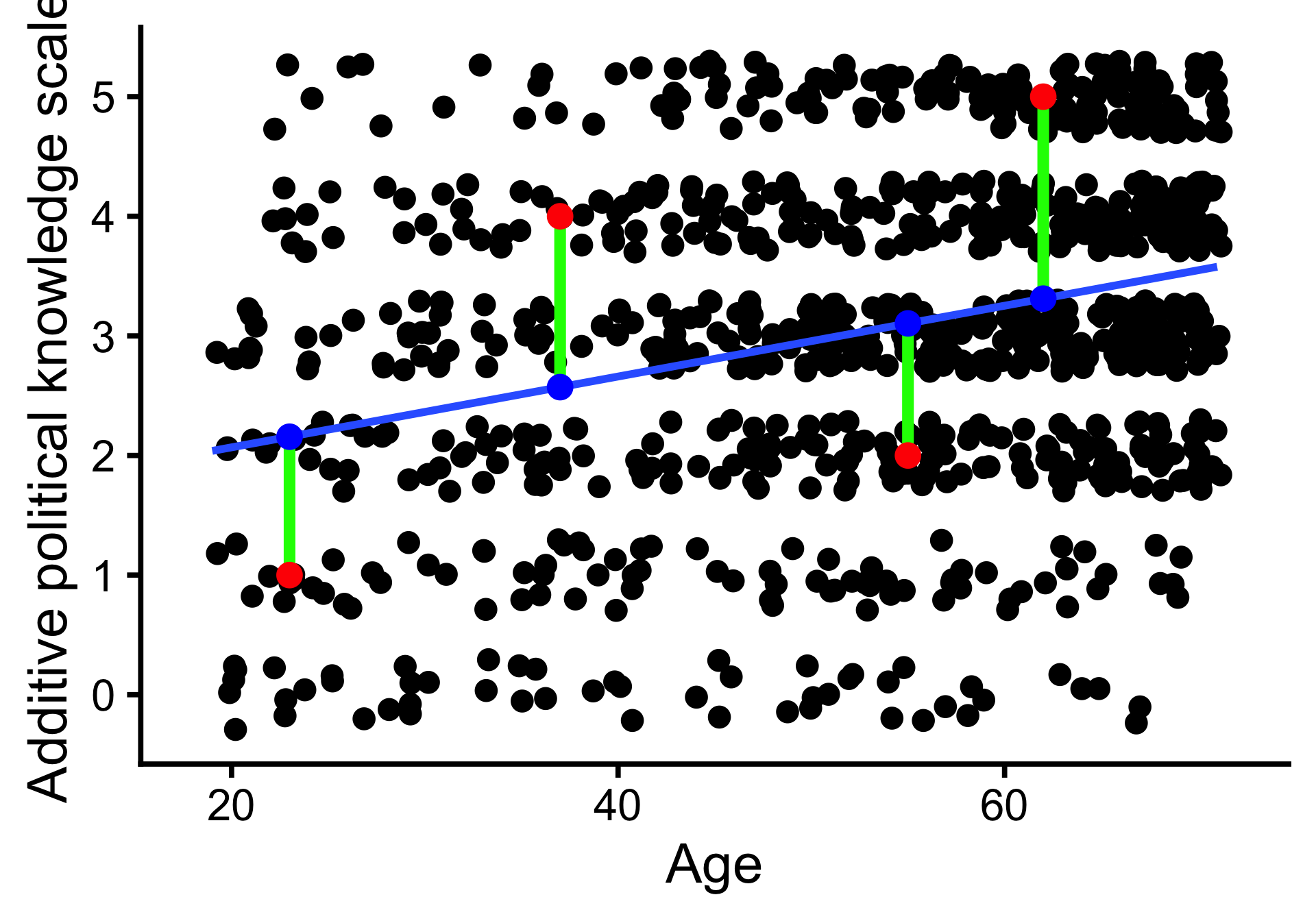
Die Regressionsgerade minimiert die Fehlerquadratsumme.
Mit OLS-Schätzung: \(b_1 = \frac{\sum (x_i - \bar{x}) \times (y_i - \bar{y})}{\sum (x_i - \bar{x})^2}\) und \(b_0 = \bar{y} - b_1 \times \bar{x}\) oder in Matrix-Notation \(\beta = (X^TX)^{-1}X^TY\)
\(R^2\)
Beispiel für vier Befragte:
| Age | y | yhat | e | e2 | e_M | e_M2 |
|---|---|---|---|---|---|---|
| 23 | 1 | 2.16 | -1.16 | 1.34 | -2.04 | 4.18 |
| 37 | 4 | 2.57 | 1.43 | 2.04 | 0.96 | 0.91 |
| 55 | 2 | 3.10 | -1.10 | 1.22 | -1.04 | 1.09 |
| 62 | 5 | 3.31 | 1.69 | 2.85 | 1.96 | 3.82 |
- \(y\): Beobachteter Wert
- \(\hat y\): Vorhergesagter Wert
- \(e\): Residuum, Vorhersagefehler
- \(\bar y\): Mittelwert
- \(e_m\): Abweichung vom Mittelwert
\(R^2 = \frac{\sum(y_i - \bar{y})^2 - \sum(y_i - \hat y)^2}{\sum(y_i - \bar{y})^2}\)
- \(R^2 = .09\): Anteil der Varianz, die das Regressionsmodell erklärt; 0 (Modell erklärt keine Varianz) bis 1 (perfekter linearer Zusammenhang). Vergleich mit Mittelwert als einfachstem Modell von \(y\).
\(R^2\)
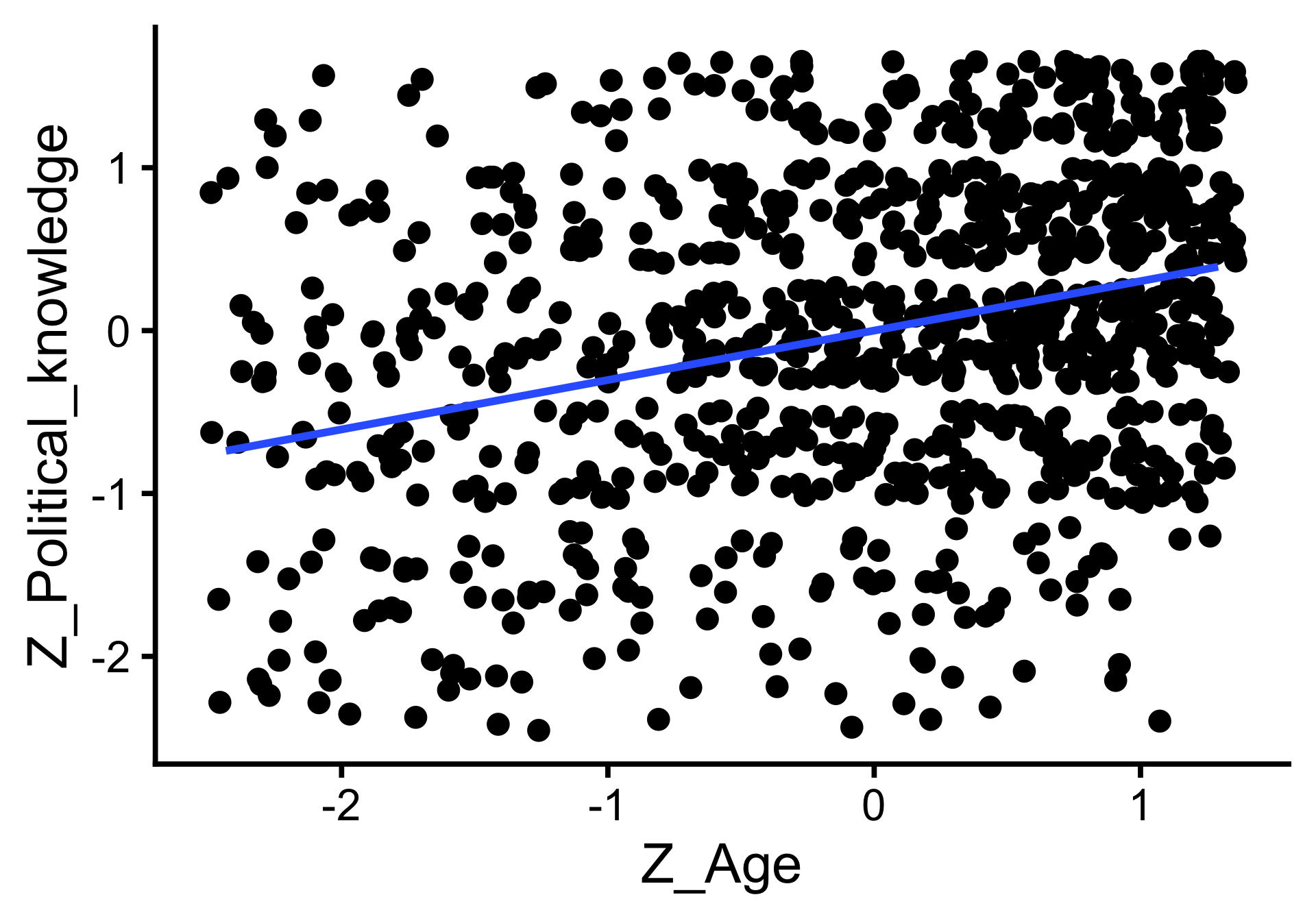
Standardisierung und (Pearsons) \(r\)
- Standardisierter Regressionskoeffizient (unter SPSS-Nutzer:innen häufig \(\beta\)): \(\beta_1 = b_1 \times \frac{SD_x}{SD_y}\)
- Schätzung nach z-Standardisierung der Daten: \((x_i - M_x) / SD_x\) mit \(M_x\) Mittelwert von \(x\) und \(SD_x\) Standardabweichung von \(x\)
- \(\text{Z_Political_knowledge} = 0.30 * \text{Z_Age}\); \(SD_{\text{Age}} = 14\), \(SD_{\text{Political_knowledge}} = 1.4\)
- Wenn das Alter um 1 SD steigt, dann steigt Political_knowledge um 0.30 SD.
- Korrelationskoeffizient Pearsons \(r\) = standardisierter Regressionskoeffizient in bivariater linearer Regression; hier: \(r = 0.30 = \beta_1\)
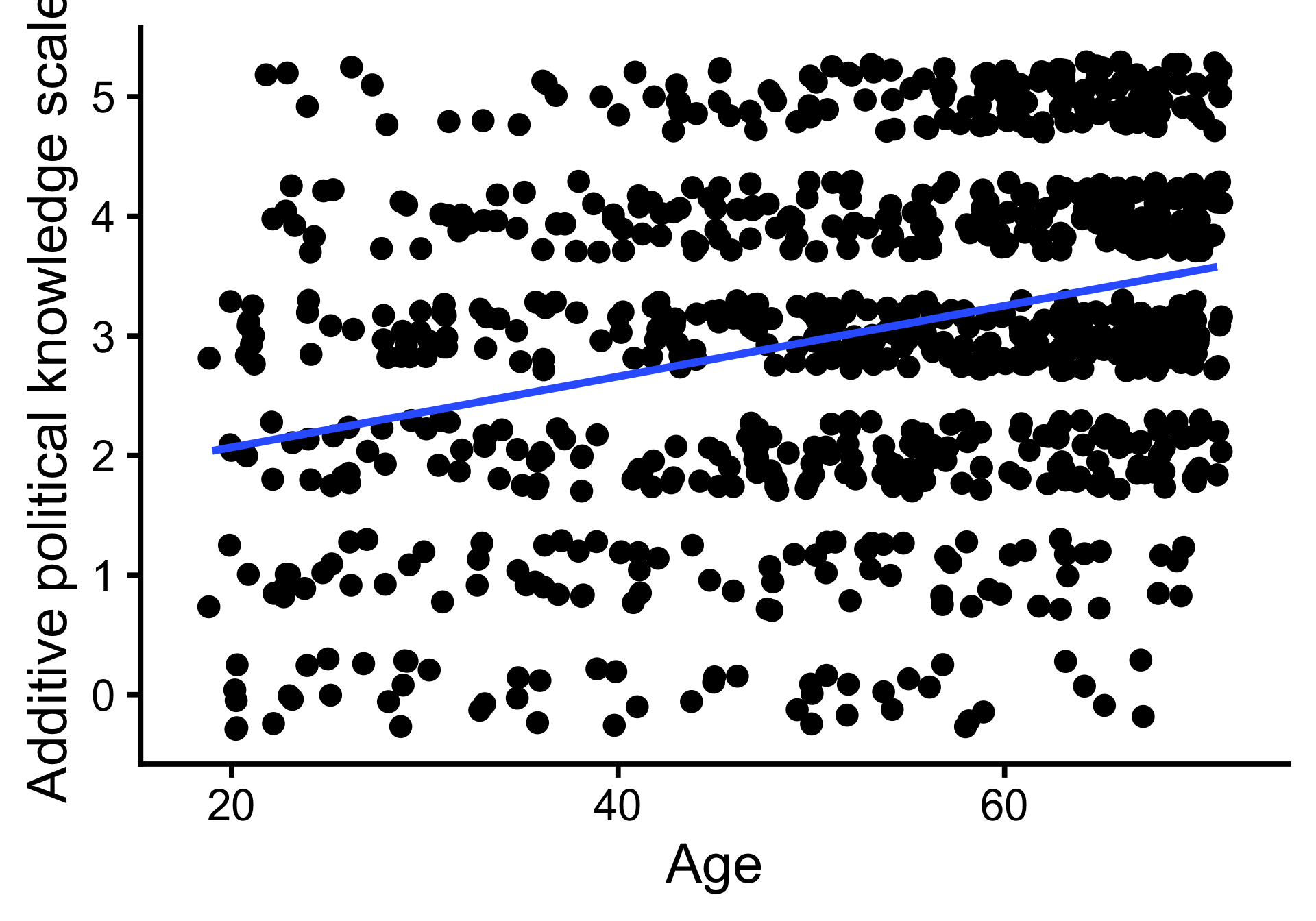
Vorhersagen: Plot
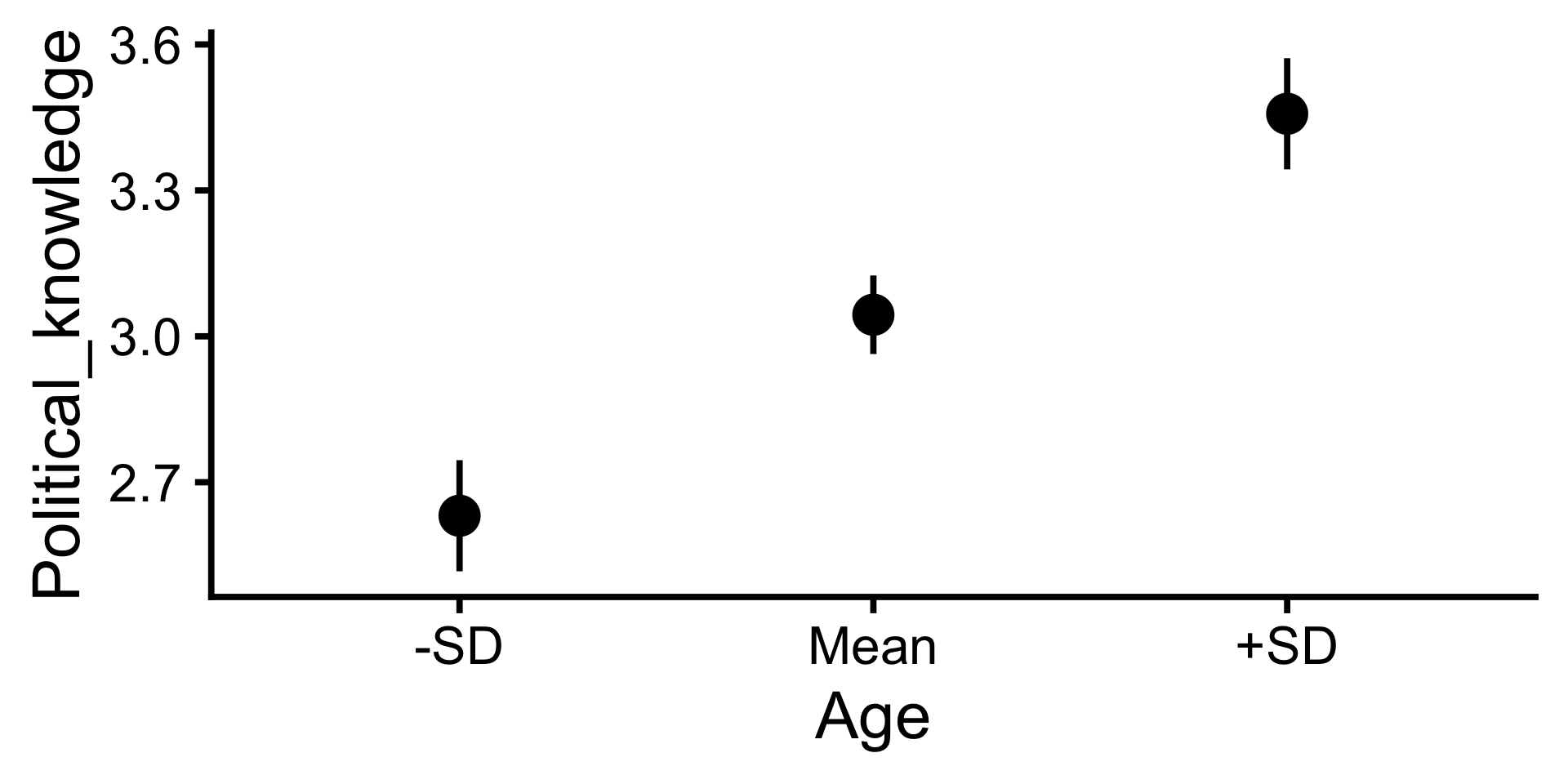
- Mit der Regressionsgleichung lassen sich Vorhersagen der abhängigen Variable für beliebige Werte der Prädiktoren machen.
- Hier: Für Personen mit unterdurchschnittlichem (M - SD), durchschnittlichen (M) und überdurchschnittlichen (M + SD) Alter
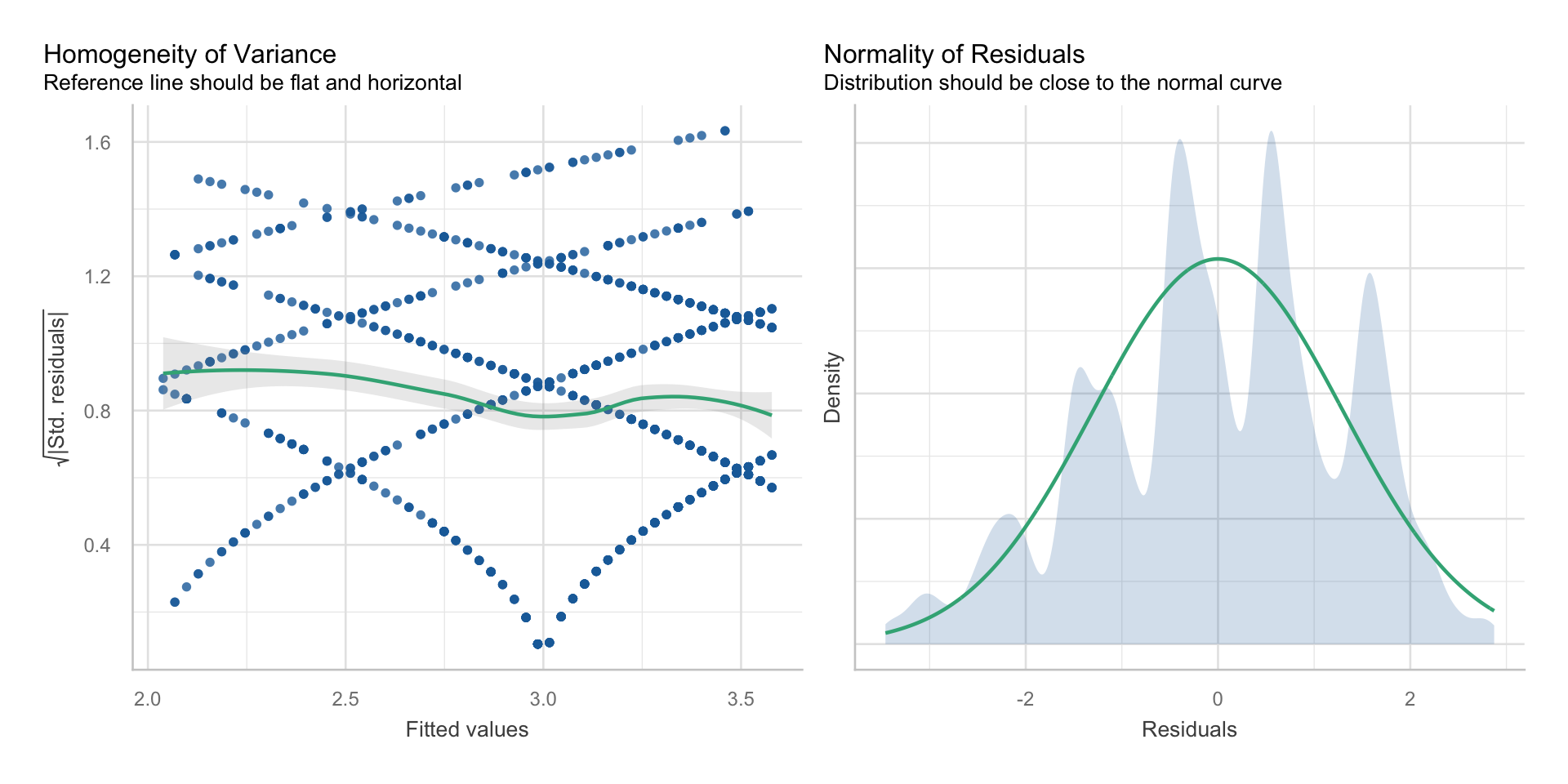
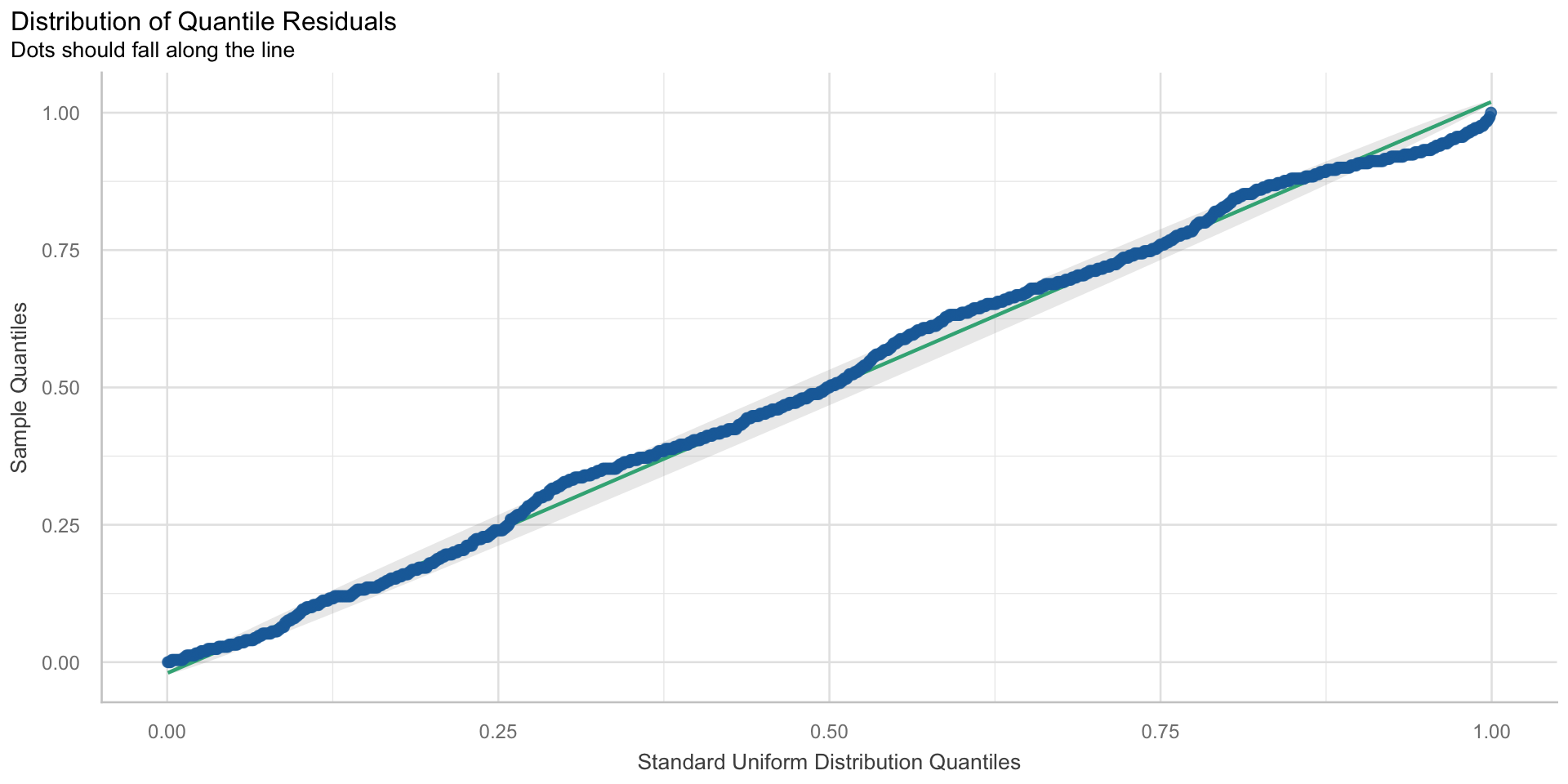
Annahmen und ihre Überprüfung
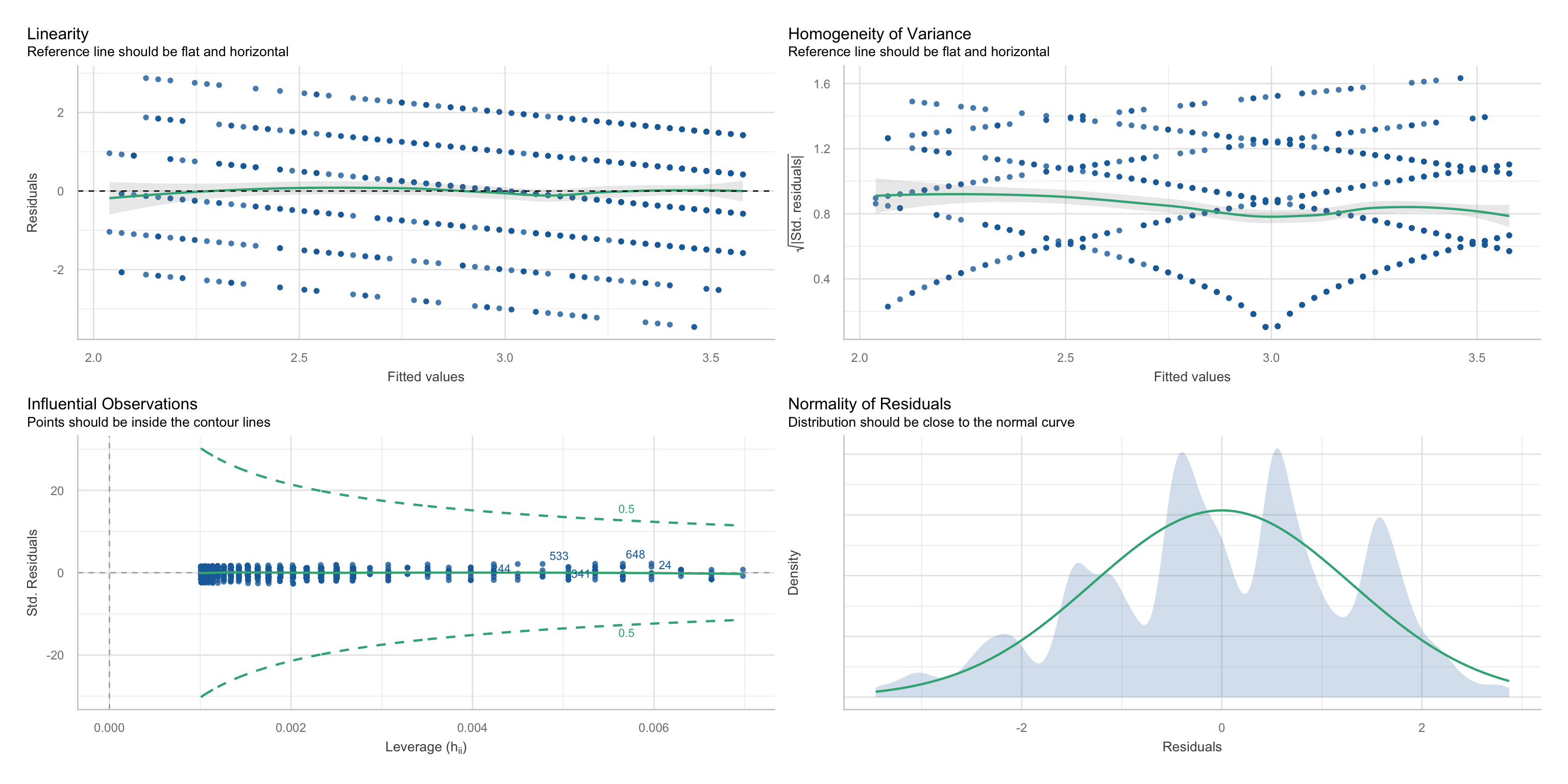
Linearität
$NCV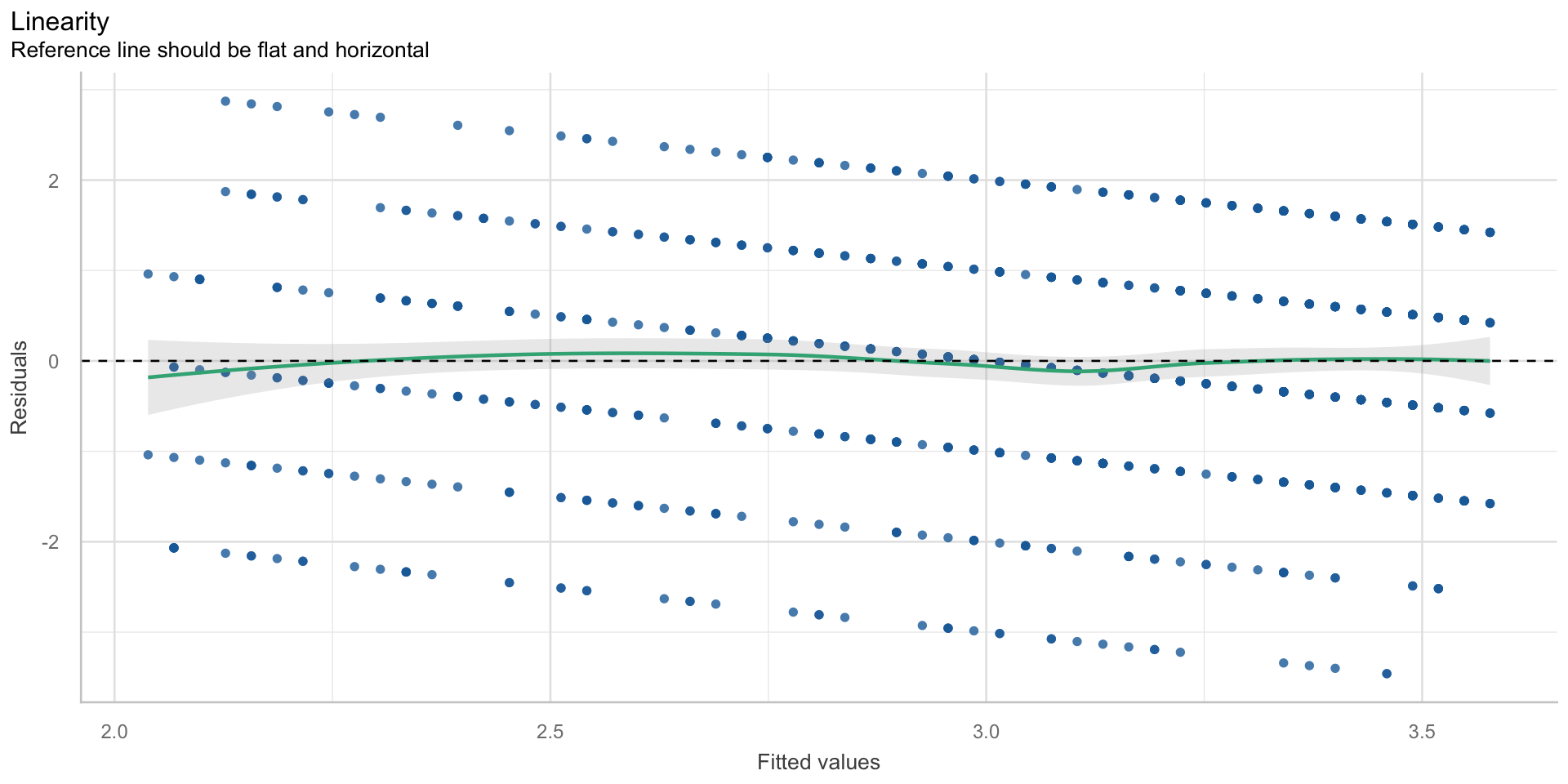
Normalverteilung und Homoskedastizität der Residuen
Unabhängigkeit der Residuen
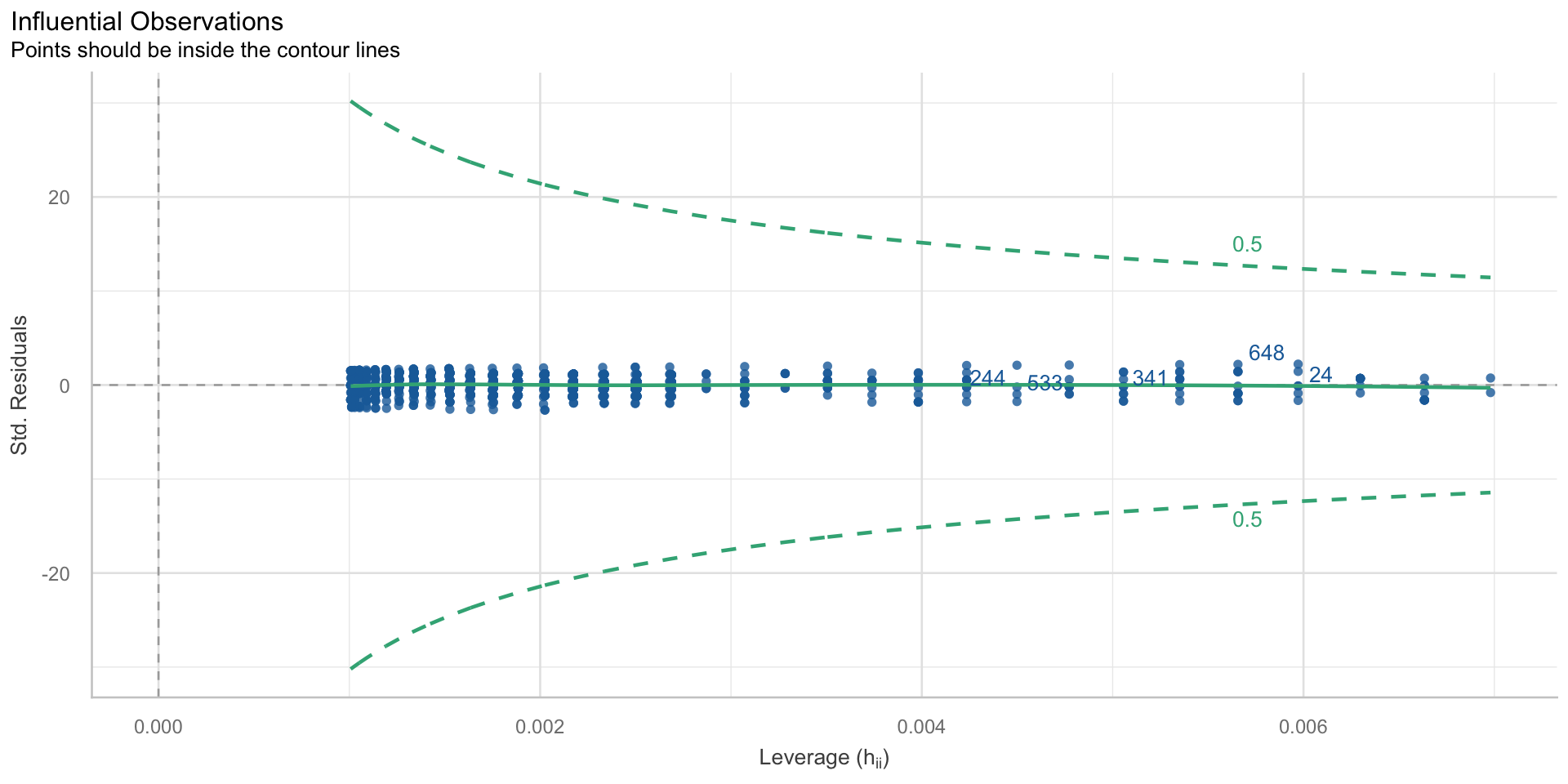
keine einflussreichen Ausreißer
Addieren & Subtrahieren einer Konstante
- Zentrieren von quasi-metrischen Prädiktoren um ihren Mittelwert
Multiplizieren & Dividieren mit einer Konst.
- Skala verändern:
- Teilen des Alters durch 10 → Vergleich zu bzw. Veränderung um 10 Jahren

Multiplizieren & Dividieren mit einer Konst.
- Z-Standardisieren: Zentrieren aller quasi-metrischer Variablen um Mittelwert und Teilen durch eine Standardabweichung → Standardisierte Koeffizienten
Nicht-lineare Transformationen
- z.B. Logarithmierung: Vergleich bzw. Veränderung in %
![]()
![]()