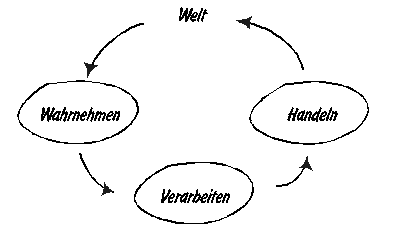
Abbildung 1: Wahrnehmen und Handeln (nach [Brooks])
FU-Berlin
WS99/00
André Vratislavsky
Ähnliche Prinzipien sind in der Natur wiederzufinden. Das Fortbewegen in einer natürlichen Umgebung z.B. ist ein Zusammenspiel geplanter und reaktiv stattfindender Bewegungen mit einem unebenen Untergrund. Während der Laufapparat die Beine in einer Vorwärtsbewegung koordiniert, müssen die Füße je nach Auftritt individuell gesteuert werden. Dabei müssen Feinkorrekturen nur an bestimmten Muskeln stattfinden. Im Ernstfall verhindert der sogenannte Stolperreflex ein Hinfallen. Dieser wird dezentral im Rückenmark gesteuert. Eine zentrale Verarbeitung im Gehirn hätte viel zu lange Wege zur Folge.
Ein ganz anderer Gedanke ist die Frage, ob technische Entwicklungen immer die Folge von neuen Anforderungen sind. Wenn z.B. ein Softwareprodukt entwickelt werden soll, so sollte auch eine geeignete Hardware entworfen werden. Tatsächlich muß man aber häufig mit vorhandener üblicher Technik auskommen., weil das Wissen darüber eine Neuorientierung nicht zuläßt. So hat sich z.B. das Von-Neumann-Rechnermodell mit einem zentralen Programm in einem zentralen Speicher durchgesetzt. Vielleicht wäre es in einigen Fällen besser, gewohnte Denkmodelle zu verlassen und sich beispielsweise an den bestehenden und seit Jahrmillionen Jahren bewährten Vorbildern der Natur zu orientieren.
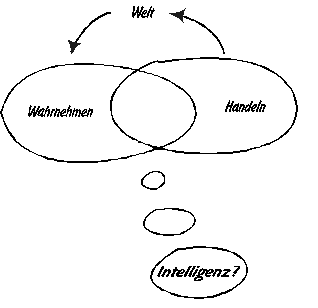
Ein Roboter, der bestimmte Aufgaben übernehmen soll, sollte sich möglichst intelligent verhalten. Was aber ist überhaupt Intelligenz? Menschen verhalten sich im Allgemeinen so, daß ein (außenstehender) Beobachter ihnen Intelligenz bescheinigt. Ist ein Roboter, der ein ähnliches Verhalten zeigt, intelligent? Kann man intelligente Computer bauen?
In diesem Referat wird im Wesentlichen auf das Buch Cambrian Intelligence von Rodney A. [Brooks] und die dort vorgestellte Verhaltensarchitektur mit reaktiver Idee eingegangen. Im Anhang befindet sich eine kurze Beschreibung des Dual Dynamic Ansatzes ([Bredenfeld 1]http://ais.gmd.de/BE/recent.html).
Ein anderes Modell sieht keinen eigenen Bereich für die Verarbeitung der Wahrnehmungen vor. Einzig der Beobachter sieht hinter den sichtbaren Ergebnissen des Handelns Intelligenz.
Abbildung 1: Wahrnehmen und Handeln (nach [Brooks])

Abbildung 2: Kontrollfluß einer sequentiellen Steuerungsarchitektur
Ein Roboter soll auch in einer beliebigen Umgebung gut funktionieren, die nicht speziell für ihn konstruiert wurde, nicht nur in Büroräumen etc. Dies erfordert u.a. ein schnelles Wiederherstellen des normalen Betriebszustandes, sobald nach einer Störung wieder sinnvolle Daten von den Sensoren kommen. D.h. das System soll sich selbst kalibrieren können.
Das System soll lange Zeit ohne äußere Unterstützung laufen.
Da der Roboter seine Umwelt von seinem Standpunkt aus "beobachtet", ist die Verwendung eines relativen Koordinatensystems mit Bezugssystem Roboter sinnvoll.
Eine interne Repräsentation der Umwelt (eine "Karte" von der Umgebung) soll vom System selbst erzeugt werden können.
Schließlich stellt sich die Frage nach den verwendbaren Sensoren. Ein optisches Bild liefert eine sehr genaue Abbildung der Umwelt. Leichter interpretierbare Sensoren wie Abstandmesser auf Ultraschallbasis etc. sind leider recht ungenau.
Für eine zuverlässige Bildauswertung wird oft ein einzelnes Bild möglichst genau analysiert. Alternativ können auch mehrere Bilder parallel verarbeitet und die endgültige Information aus den Teilergebnissen zusammengesetzt werden. Bei diesem Verfahren ist viel redundante Information vorhanden, es ist aber u.U. leichter und weniger fehleranfällig, über mehrere ungenaue Informationen zu mitteln als direkt eine einzelne konsistente Abbildung der Umwelt zu generieren.
Das Bild einer fest auf dem Roboter montierten Kamera hängt von seiner Ausrichtung ab. Um ein Objekt zu analysieren, kann bei solch einem passiven Vision System nur ein vorgegebenes Bild, welches z.B. nicht die wesentlichen Landmarken fokussieren kann, verwendet werden. Ein aktives Vision System hingegen erlaubt wie beim Menschen ein Objekt abzutasten und auf diese Weise eine beliebig große Informationstiefe zu gewinnen.
Um Signalwege zu sparen und das System übersichtlicher zu machen,
sollte die Information der Sensoren möglichst in Sensornähe vorverwertet
werden. Mit Hilfe von Differenzbildung und ähnlichen einfachen Operationen
können z.B. sich bewegende Strukturen erkannt werden [Möller
1]. Dieses Verfahren findet auch beim Wirbeltierauge Verwendung. Auch
ohne die Objekte zu identifizieren können diese Informationen schon
für wichtige Funktionen genutzt werden wie Kursstabilisierung, Hindernisvermeidung,
Verfolgung von beweglichen Zielen, Objekt-Hintergrund-Trennung. Ein teilweise
vorverarbeitetes Bild kann dann an die entsprechenden Stellen weitergeleitet
werden.
Jede Schicht ist physikalisch ein eigenes Modul und besteht gegebenenfalls aus Untermodulen. Alle Module arbeiteten asynchron, können aber kommunizieren. Höhere Schichten können in niedrigere eingreifen, indem sie ihre Outputs hemmen, bzw. ersetzen.
Das ganze System kann jederzeit durch höhere Schichten mit erweiterter Funktionalität verbessert werden. Dabei bleiben die unteren Schichten unverändert in ihrer Funktion erhalten.
Anzumerken ist, daß die eingangs erwähnte sequentielle Architektur sich teilweise innerhalb der Schichten wiederfindet.

Abbildung 3: Kontrollfluß der Subsumption Steuerungsarchitektur
Ein Modul kann als Zustandsautomat aufgefaßt werden, welcher in Abhängigkeit von seinem Zustand und dem Input einen neuen Zustand betritt und einen Output erzeugt. Da jedes Modul im Prinzip selbständig arbeitet, kann ihre Gesamtheit als System von nebenläufigen Prozessen angesehen werden, die untereinander Nachrichten austauschen. Dabei können Daten verloren gehen. Es gibt keinen zentralen Speicher und keine zentrale Kontrolle über die einzelnen Module.
Jedes Modul besitzt gepufferte Eingänge und Ausgänge. Treffen mehrere Nachrichten schnell hintereinander ein, so wird u.U. nur die aktuellste verarbeitet. Inputs können von anderen Modulen ersetzt, Outputs gehemmt werden. Auf diese Weise können höhere Ebenen die Funktion der unteren Ebenen ergänzen.
Im Folgenden wird ein Beispiel einer Steuerungsarchitektur
aus [Brooks] (Rodney
A. Brooks, Cambrian Intelligence, 1999) vorgestellt,
das dort auch implementiert und getestet wurde.
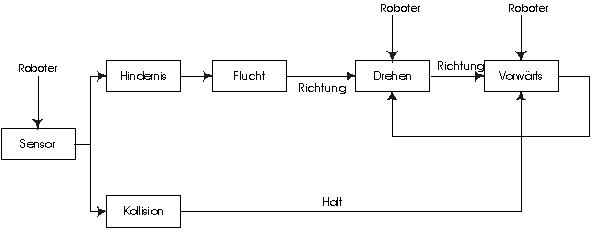
Abbildung 4: Ebene 1
Das Sensor-Modul wertet die Daten der Roboter-Sensoren aus und liefert eine Karte mit Hindernissen. Dafür werden der Einfachheit halber Polarkoordinaten mit Bezugssystem Roboter verwendet.
Das Hindernis-Modul faßt alle Daten über Hindernisse (vor allem auch bewegte Hindernisse) zu einer für die Fahrtrichtung unmittelbar relevanten Information zusammen. Das Flucht-Modul errechnet falls notwendig daraus einen "Fluchtweg", bestehend aus Richtungsänderung und Länge eines in die neue Richtung zu fahrenden Weges.
Das Drehen-Modul veranlaßt den Roboter, seine Fahrtrichtung
um den empfangenen Winkel zu ändern und leitet die Nachricht weiter
an das Vorwärts-Modul. Dann tritt es in einen Wartezustand,
in dem alle eingehenden Nachrichten ignoriert werden. Das Vorwärts-Modul
veranlaßt den Roboter, das in der Nachricht genannte Stück vorwärts
zu fahren. Falls eine "Halt"-Nachricht vom Kollision-Modul kommt,
wird das Fahren jedoch sofort unterbrochen. Sobald die Fahraktion beendet
ist, sendet das Modul eine Nachricht an das Drehen-Modul, welche
dieses wieder empfangsbereit macht. Eine neue "Flucht"-Aktion kann also
erst nach Vollendung oder Abbruch der alten (wegen unmittelbarem Hindernis)
entgegengenommen werden.
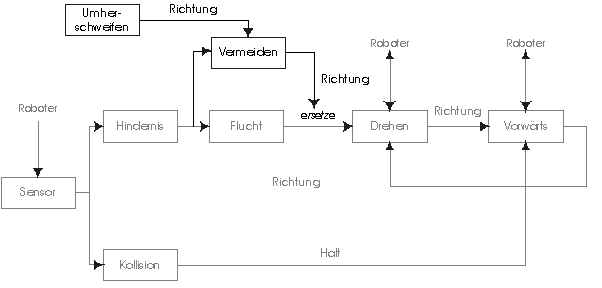
Abbildung 5: Ebene 2
Das Umherschweifen-Modul generiert in gewissen Zeitabständen eine neue Richtungsinformation in gleichem Format wie die des Flucht-Moduls. Dies können beliebige "Fahrtwünsche" sein, die anstatt der Information des Flucht-Moduls verwendet werden können. Um bei Hindernissen nicht mit der Information des Flucht-Moduls in Konflikt zu geraten, was zum Halten durch das Kollision-Modul führen würde, wird die neue Richtung vom Vermeiden-Modul überprüft bzw. modifiziert. Das Vermeiden-Modul der Ebene 2 erweitert somit die Funktion des Flucht-Moduls in Ebene 1.
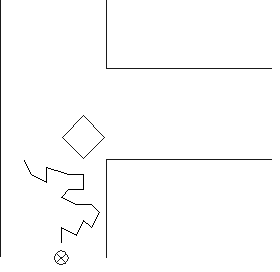
Abbildung 6: Mit der Steuerungsarchitektur aus Ebene
1 und 2 fährt der Roboter einen ziellosen Zickzackkurs ohne Kollisionen.
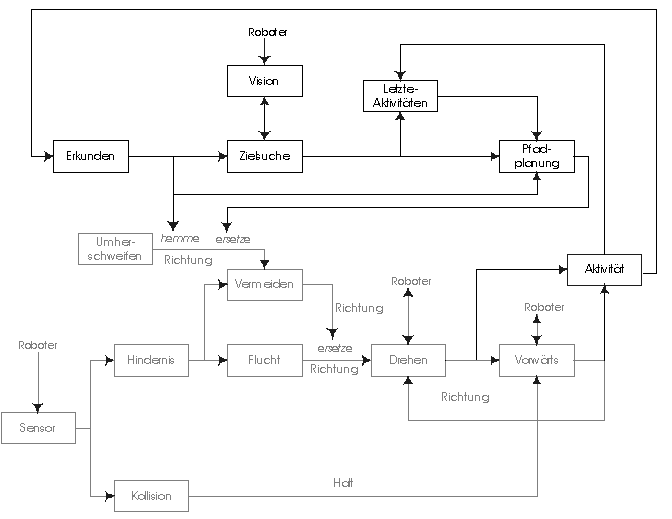
Abbildung 7: Ebene 3
Das Aktivität-Modul bemerkt eine abgeschlossene Dreh-Fahr-Handlung und sendet Informationen darüber an die eigentlichen Module der dritten Ebene.
Das Erkunden-Modul empfängt Informationen über die Tätigkeit des Roboters und kann ein Erkundungsverhalten starten. Dazu hemmt es den Ausgang des Umherschweifen-Moduls, damit die aktuelle Ausgangsposition des Roboters nicht mehr unnötig verändert wird, und setzt das Pfadplanung- und Zielsuche-Modul in den Startzustand.
Das Zielsuche-Modul sucht mit Hilfe des Vision-Moduls nach möglichen anzusteuernden Zielen, z.B. Korridoren, und sendet diese zum Pfadplanung-Modul.
Das Pfadplanung-Modul wählt unter Berücksichtigung eines übergeordneten Ziels (z.B. möglichst weit in eine Richtung tendenziell nach rechts zu fahren) ein Fahrtziel aus den möglichen des Zielsuche-Moduls aus. Es errechnet unter Berücksichtigung der letzten Aktivitäten, die das Letzte-Aktivitäten-Modul akkumuliert, Richtungsinformationen, die die zufällig generierten Richtungen des Umherschweifen-Moduls ersetzen.
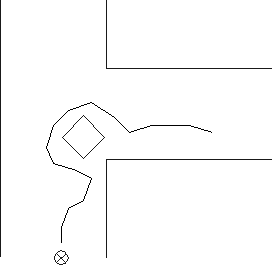
Abbildung 8: Mit der Steuerungsarchitektur aus Ebene
1, 2 und 3 fährt der Roboter einem Ziel entgegen. In diesem Fall ist
das Ziel, möglichst weit zu fahren und sich dabei rechts zu halten.
Anzumerken wäre, daß die hier nicht näher spezifizierten Module für sich keine hoch intelligenten Aufgaben erfüllen, sondern nach einfachen Prinzipien verfahren. So werden z.B. beim Zielsuche-Modul nur einfache Bildinformationen ausgewertet. Große zusammenhängende Flächen im unteren Bereich eines Umgebungsbildes stammen z.B. mit hoher Wahrscheinlichkeit vom Fußboden eines Gebäudes. Ihre Form kann zur Fahrtrichtungswahl herangezogen werden. Das Pfadplanung-Modul wählt aus einer Liste von potentiellen Zielen nach einfachen statistischen Methoden ein Ziel aus.
Das System läßt sich in weiteren Schichten um höhere
Funktionalität erweitern.
Bei der Suche erfolgt keine Ausrichtung auf ein Ziel. Dieses wird durch Abfahren eines Pfades, z.B. einer Spirale, zufällig gefunden.
Beim Richtungsfolgen z.B. nach einem Kompaß, wird kein Ziel wahrgenommen. Beim Zielfolgen (Taxie) richtet sich der Agent auf das Ziel aus, indem er einen auffälligen Reiz, z.B. ein helles Licht oder eine Duftspur, verfolgt.
Die von [Braitenberg] vorgestellten Vehikel verarbeiten Sensorsignale in einfachen Verstärkerschaltungen direkt zu Motorspannungen. Mit zwei Lichtsensoren und zwei Motoren kann ein Vehikel gebaut werden, das einer Lichtquelle folgt. Dazu ist also keine explizite Verhaltenssteuerung notwendig, insbesondere wird kein Speicher für Daten benötigt. Die Braitenberg Vehikel lassen sich leicht in ihrer Funktionalität erweitern. So lassen sich Vehikel bauen, die "gemeinsam" einen Gegenstand wegschieben, indem sie nur in einer Richtung auf ein leuchtendes Objekt zufahren. Die Richtungskontrolle kann dabei durch einen eingebauten Kompaß vorgenommen werden. Dieses Verhalten ergibt sich aus der reaktiven Steuerung und sollte nicht zu hoch interpretiert werden. Braitenberg Vehikel haben keine inneren Zustände.
Bei der Führung bestimmt nicht das Ziel selbst, sondern die Anordnung der umgebenden Objekte bzw. Reize den Weg.
Bei der Wegintegration werden Entfernungen und Richtungen zurückgelegter Strecken im Fluge zu einem resultierenden direkten Rückweg integriert. Es sind nur einfache Berechnungen und ein minimaler Speicher notwendig.
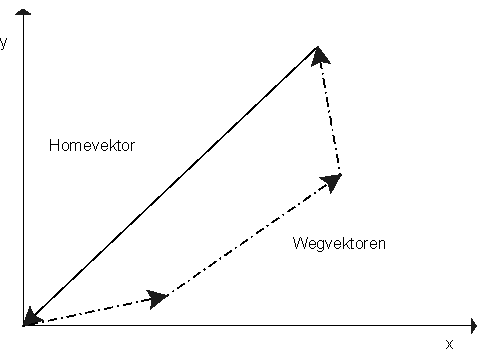
Abbildung 9: Wegintegration
Mit diesen Navigationsmethoden kann nur ein Ziel gefunden werden, wenn während des gesamten Weges derselbe Reiz bzw. dieselbe Reizkombination wahrnehmbar ist. Führt der notwendige Weg über unterschiedliche Reizsituationen, so müssen mehrere Orte erkannt werden. Das Wegfinden erfordert eine gespeicherte Repräsentation dieser Orte. Diese müssen erkannt werden und ein bestimmtes Verhalten auslösen (Erkennungsgesteuerte Reaktion). Für zwei Orte ist der verbindende Weg vorbestimmt. Ist dieser versperrt, so kann der Agent nicht angemessen reagieren.
Eine Lösung wäre, eine alternative Route zu fahren (Topologische Navigation). Dafür müssen alle gespeicherten Routen zu einem Gesamtplan verschmolzen sein. Es reicht nicht, jedem Ort der Repräsentation ein Verhalten zuzuordnen, gleiche Orte müssen erkannt werden, also nicht doppelt in der Repräsentation existieren. Der Plan kann als Graph dargestellt werden, Orte entsprechen den Knoten, fahrbare Verbindungen den Kanten.
Mit dieser Navigationsmethode können nur bekannte Routen gefahren
oder neue durch Suchen gefunden werden. Es ist nicht möglich, aus
dem vorhandenen Plan auf nicht gespeicherte Abkürzungen zu schließen.
Dafür wäre eine globale Übersicht notwendig, ein Bezugssystem
für alle Orte und deren räumliche Beziehung (Übersichtsnavigation).
Das grundsätzliche Problem dabei ist, ein mit Meßfehlern behaftetes zweidimensionales Bild mit einem eventuell unkorrekten gespeicherten zu vergleichen und trotzdem Gemeinsamkeiten feststellen zu können. Ein pixelweiser Vergleich unbearbeiteter Bilder auch innerhalb gewisser Fehlerschranken ist wenig aussichtsreich, da sich Bilder von gleichen Positionen z.B. bei unterschiedlichem Lichteinfall stark unterscheiden können. Es muß zumindest eine gewisse Bildbearbeitung wie Segmentierung stattfinden.
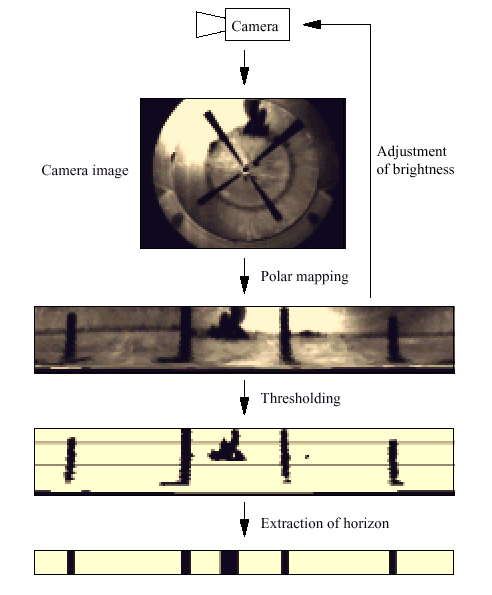
Abbildung 11 (aus: Insect Strategies of Visual Homing
in Mobile Robots - Ralf Möller, Dimitrios Lambrinos, Thorsten Roggendorf,
Rolf Pfeifer, Rüdiger Wehner [Möller 2]
(http://www.ifi.unizh.ch/groups/ailab/people/moeller/documents/AAAI98.ps.gz)
): Das Snapshot Modell verwendet ein eindimensionales Panorama, also ein
um den Horizont laufendes Band mit unterschiedlichen Sektoren, welches
auf Grundlage eines 360° Panoramabildes errechnet wird. Dieses Modell
ist in einfachen Umgebungen mit wenigen deutlichen Landmarken einsetzbar.
Aus dem Panoramabild werden große Gebiete mit anderer Helligkeit
zu Segmenten entsprechender Größe abstrahiert. Es werden keine
Objekte, sondern nur optische Muster unterschieden. Um das gewonnene Panorama
mit einem gespeicherten vergleichen zu können, müssen sich beide
auf dieselbe Orientierung beziehen. Dazu muß der Agent einen Kompaß
besitzen. Aus den Unterschieden beider Panoramen wird ein Homevektor berechnet,
der auf den Ort zeigt, wo kein Unterschied zum gespeicherten Bild existieren
würde. Nachteil des Systems: Die optischen Quellen dürfen nicht
verdeckt sein.
Ein zweidimensionales Bild sagt zuwenig über die wirkliche Welt
aus. Dafür müssen Objekte identifiziert und ein dreidimensionales
Modell entwickelt werden. Dabei ist es zweckmäßig, keine Feinheiten
sondern nur auffällige Merkmale, also z.B. große Objekte wie
Wände und Korridore als Landmarken heranzuziehen. Diese können
trotz kleinerer Meßfehler relativ sicher erkannt werden.
Bei der Subsumption Architektur nach [Brooks] wird diese Karte nicht in einer zentralen Datenstruktur nach Von-Neumann Art gespeichert, sondern verteilt in den Kontrolleinheiten. Auch für die Verhaltensstrategien bzw. Verhaltenspläne muß es keine zentrale Datenstruktur bzw. zentrales Programm geben. Vielmehr steht intelligentes Verhalten in einem engen Zusammenhang mit der Umwelt, es ergibt sich erst aus der Interaktion mit ihr (siehe dazu auch [Christaller]). Verhalten ist zwar durch die Architektur der einzelnen Komponenten des Systems bestimmt, die Idee des Verhaltens ist aber nirgends als Programm abgelegt, sondern durch die variable Verschaltung des Systems definiert. Für den Beobachter ist es letztendlich egal, ob die Repräsentation der Umgebung und die Verhaltensstrategien in einer abrufbaren Datenstruktur vorhanden sind oder auf andere Weise zur Wirkung kommen. Letztendlich zählt nur das resultierende sichtbare Verhalten. Bei der Subsumption Architektur hängen Verhalten und Kenntnis der Umgebung eng zusammen und sind über weite Bereiche des Steuerungssystems verteilt. Die Umgebung wird in diesem veränderlichen Schaltungsnetz repräsentiert, der Auswertung der Sensordaten, die Modellbildung und die Entscheidung über Aktionen wird vom gesamten System übernommen.
Zur Verarbeitung räumlicher Informationen ist ein Koordinatensystem
und ein zugehöriges Bezugssystem notwendig. Diese sollten so gewählt
werden, daß die Berechnungen möglichst einfach sind. Für
eine globale Robotersteuerung in einer global erfaßten Umwelt (fest
montierte Kamera) eignet sich ein über die Landschaft gelegtes Gitternetz
(kartesisches Koordinatensystem), da jeder Punkt gleich wichtig ist. Für
die Erfassung eines Objekts mit einem aktiven Vision System eignet sich
als Bezugspunkt das (bewegte) Objekt und Polarkoordinaten. Auch für
Roboter mit eigenen Sensoren und eigener lokaler Steuerung liegt es nahe,
den Bezugspunkt in den Roboter zu legen und Orte durch Entfernungen und
Winkel zu Längsachse (Polarkoordinaten) zu beschreiben, da dies die
unmittelbar meßbaren Informationen sind.
Der beim Umfahren eines Objekts abgefahrene Weg ergibt sich dynamisch
während der Fahrt und kann als Beschreibung des Objekts angesehen
werden. Der Landmarkenerkennungsalgorithmus von [Brooks]
bezieht Informationen über die Umgebung aus der Art der Bewegungen
des Roboters. Dabei wird die Annahme verwendet, daß ein bestimmter
Ort eng mit einem bestimmten Bewegungsmuster zusammenhängt. Dies macht
in labyrinthartigen Umgebungen wie Büroräumen, wo an einem bestimmten
Ort nur wenige sinnvolle Verhalten möglich sind, einen Sinn. Eine
Landmarke enthält Informationen über Ausrichtung des Roboters,
Kurven und Abstände zu Objekten. Dabei ist jede Landmarke nur als
Hypothese anzusehen, d.h. die Information kann u.U. auch falsch sein. Die
Meßdaten einer Landmarke werden mit den vorhandenen Daten verglichen.
Wird innerhalb eines gewissen Bereichs eine Übereinstimmung gefunden,
gilt die Landmarke als wiedererkannt. Es werden also keine absolut korrekten
Meßwerte benötigt, das System arbeitet mit geschätzten
Informationen der Umwelt. Diese müssen allerdings gut genug sein,
um ein konsistentes Modell der Umwelt zu liefern, mit dem sinnvoll gearbeitet
werden kann. Immer wenn eine Landmarke wiedererkannt ist, werden die neuen
Beschreibungsdaten mit den alten verrechnet, so daß die Landmarke
durch einen über die Zeit laufenden Mittelwert definiert wird, der
Meßfehler oder nur vorübergehend erscheinende Objekte wie herumlaufende
Personen heraus mittelt.
Der Roboter bahnt sich während seines Explorationsverhaltens seinen Weg durch den Graphen, der Knoten des jeweiligen Aufenthaltsortes des Roboters heißt aktiver Knoten. Dieser sendet eine Aktivierungsnachricht an seine Nachbarn in Wegrichtung und eine Deaktivierungsnachricht an seinen Vorgänger.
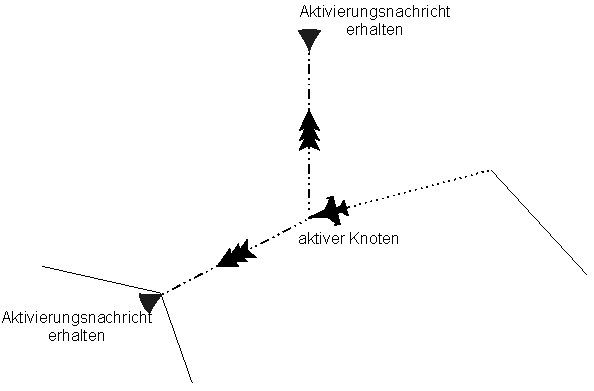
Abbildung 12: Senden einer Aktivierungsnachricht
Der Roboter fährt in eine beliebige Richtung weiter und entdeckt die nächste Landmarke. Dieser Weg erfolgt nicht unbedingt entlang einer Kante. Die wahrgenommenen Informationen über die erreichte Landmarke werden per Broadcast über spezielle Leitungen an alle Knoten des Graphen gegeben. Diese vergleichen sie parallel, d.h. in konstanter Zeit mit ihren eigenen Informationen über sich. (Diese Informationen könnten z.B. folgende Bedeutung haben: Auf dem Weg nach Norden nach links abbiegen, rechts und geradezu in 20 cm Entfernung befindet sich eine Wand.) Hat kein Knoten eine Übereinstimmung, so wurde eine neue Landmarke gefunden und die Daten darüber werden in einen leeren Nachbarknoten des aktiven Knotens eingetragen.
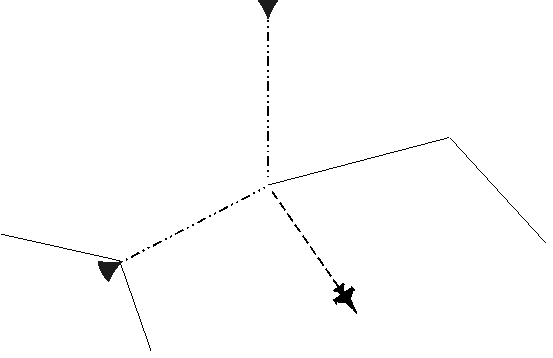
Abbildung 13: Eine unbekannte Landmarke wurde entdeckt
Findet ein Knoten, der zuvor eine Aktivierungsnachricht erhalten hatte, eine Übereinstimmung, so befindet sich der Roboter auf einem bekannten Weg. Hat nur ein Knoten ohne Nachricht eine Übereinstimmung, so liegt eine Verwechslung vor oder eine neue Kante muß eingetragen werden, weil der Roboter z.B. um ein Objekt herum eine Schleife gefahren ist. Die neue Kante wird in einer Liste vermerkt. Diese Liste hat eine lineare Größe, da die Knoten statistisch betrachtet nur eine konstante Anzahl von Nachbarn haben, denn es gibt normalerweise nur begrenzt viele Verzweigungen.
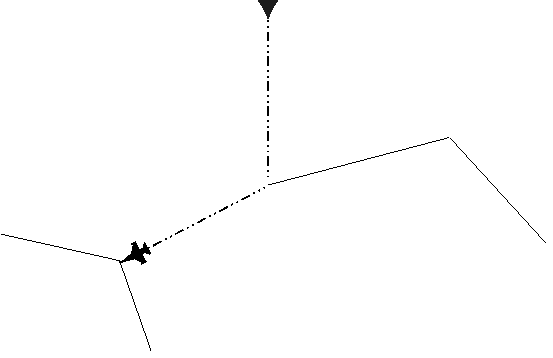
Abbildung 14a: Eine bekannte Kante wurde befahren
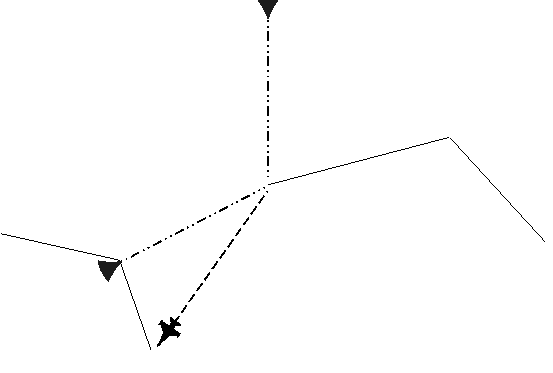
Abbildung 14b: Eine neue Kante zu einer bekannten Landmarke
wurde gefunden
Wenn es ähnliche Landmarken an verschiedenen stellen der Umgebung
gibt, können falsche Schleifen entstehen. In solchen Landschaften
sind mehr Unterscheidungsmerkmale nötig. Dieser Algorithmus berücksichtigt,
ähnlich wie beim menschlichen Orientierungssinn, nicht die absolute
Position des Roboters. Es kann jedoch eine relative Ortsinformation gewonnen
werden, wenn die Fahrtgeschwindigkeit berücksichtigt wird. Zwei nah
beieinander liegende Landmarken mit gleichen Daten können nicht den
gleichen Ort repräsentieren. Immer wenn eine Übereinstimmung
ohne Aktivierungsnachricht vorliegt, kann dieses Kriterium hinzugezogen
werden. Kleinere falsche Schleifen können so vermieden werden, wenn
man annimmt, daß kein Ort innerhalb kurzer Zeit mehrfach durchfahren
wird.
Der Zielknoten sendet eine Suchnachricht an seine Nachbarn. Diese wird jeweils in Ausbreitungsrichtung weitergeleitet. Sobald die Nachrichtenfront den aktiven Knoten trifft, wählt der Roboter die entsprechende Richtung, aus der die Nachricht kam. Ohne zentrale Datenstruktur hat der Roboter keine zusammenhängende Beschreibung eines Pfades. Jeder Knoten enthält nur lokale Informationen über die einzelnen Schritte. Der Roboter kann gewissermaßen nicht von seinem Pfad abkommen. Er wartet in jedem Knoten jeweils die nächste Nachricht ab, der Pfad ergibt sich dann von selbst.
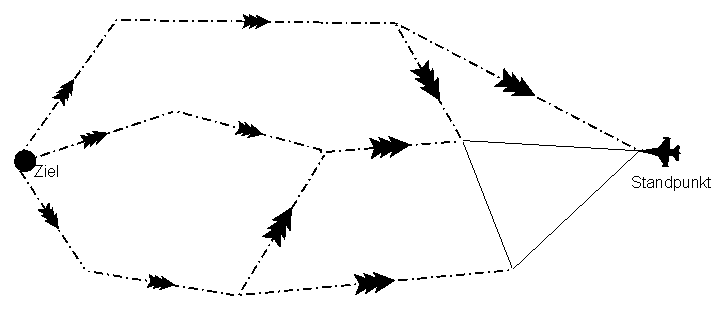
Abbildung 15: Ausbreitung einer Suchnachricht
In mehreren Explorationen derselben Umgebung werden nicht immer dieselben Pfade befahren. Die Landmarken werden unterschiedlich häufig durchfahren. Je häufiger eine Landmarke getroffen wird, um so größer ist die Wahrscheinlichkeit, daß sie auf dem physikalisch besten Weg liegt. Diese Eigenschaft kann als zusätzliches Beschreibungsmerkmal der Landmarken verwendet werden. Dazu erhält jede Landmarke einen Wert, der um so kleiner ist, je häufiger sie bei Explorationen befahren wird.
Während einer Suchnachricht werden diese Werte aufsummiert. Treffen mehrere Nachrichten an einem Knoten ein, wird der Pfad mit der kleinsten Summe gewählt.
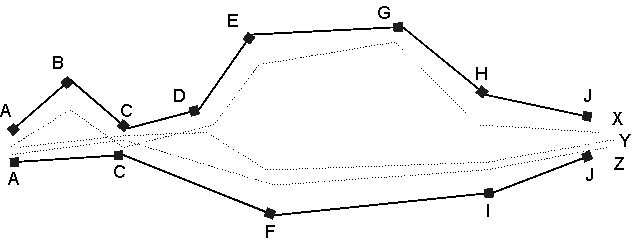
Abbildung 16: Ein Beispiel: A bis J sind die Landmarken.
A, C, J stellen Durchfahrten dar, die anderen Landmarken sind auffällige
Objekte. Ein einzelner Explorationspfad X, Y oder Z verläuft an einer
Wand entlang im Bereich des optimalen Abstands. Der Pfad von J über
die Landmarken I, F, C nach A hat den besten Wert aller Suchnachrichten
von A nach J und würde zum Finden eines bekannten Zieles verfolgt
werden.
Es sei dahingestellt, ob höhere intelligente Funktionen durch eine reaktive Architektur simuliert werden können. Auf alle Fälle sind Kombinationen denkbar. Ein reaktives Steuerungssystem steuert z.B. die in Echtzeit laufenden grundlegenden Verhaltenselemente. Diesem System wird eines zur langfristigen Planung aufgesetzt, welches seine Daten in die reaktiven Schichten einschleust.
R. Möller [Möller 3] führt
Experimente mit analoger Schaltungstechnik durch. Die Funktionsweise analoger
Schaltungen ähnelt der neuronalen Verarbeitung im Nervensystem in
gewisser Weise. Es werden analoge Signale ohne exakte Genauigkeit verwendet,
die Verarbeitung erfolgt asynchron und parallel, neuronale Operationen
wie die Addition von Strömen sind direkt möglich, die Leistungsaufnahme
ist extrem klein. Die parallele Verarbeitung ermöglicht eine sehr
hohe Geschwindigkeit auch bei größeren Schaltungen.
Agenten nach [Braitenberg] oder mit oben beschriebener Subsumption Architektur werden vom Beobachter gelegentlich mit Attributen wie zielstrebig, anhänglich oder intelligent in Verbindung gebracht. Es bedarf einer genaueren Analyse, um zu prüfen, ob solche Begriffe gerechtfertigt sind. Entsprechend ist es fraglich, ob rein reaktive Systeme mit solchen Eigenschaften gebaut werden können. Dahinter steht die Frage, ob Intelligenz eine eigenständige Eigenschaft oder nur ein Begleitphänomen ohne Repräsentation ist. Im ersten Falle wäre Intelligenz vermutlich eng an ein Gehirn im biologischen Sinne gebunden, Aussicht auf Simulation gäbe es dann wahrscheinlich nur bei Simulation des gesamten Gehirns. Im letzteren Falle besteht in vielerlei Hinsicht eine Chance, Intelligenz als Nebenprodukt zu erhalten. Es bleibt aber immer die Frage, ob die simulierten Eigenschaften letztendlich wirklich die gleichen Qualitäten haben wie ihr Original. Es wäre sicherlich anmaßend, intelligente Phänomene zu stark reduziert zu betrachten.
Ein Mensch verhält sich in einer bestimmten Art und Weise, eine ganze Gesellschaft zeigt erstaunlicher Weise Verhaltenselemente, welche im Vergleich zu denen ihrer einzelnen Mitglieder eine neue Qualität zu haben und erst als Produkt einer Vielzahl von Teilen zu entstehen scheinen. Es gibt daher die Ansicht, daß Intelligenz bei einer gewissen Komplexität entsteht. Möglicher Weise wird irgendwann ein Roboter gebaut, der ohne die Planung seines Konstrukteurs ein Verhalten einer neuen nicht eingeplanten Qualität hat.
Es ist u.U. nicht unbedingt einfach oder überhaupt möglich zu entscheiden, an welcher Stelle in einem System Intelligenz lokalisiert ist. Intelligenz könnte, wie im Beispiel der internen Repräsentation der Umwelt, im System verteilt, also nicht an ein bestimmtes Modul gebunden sein. Analog zur oben beschriebenen Navigationsarchitektur könnte ein intelligentes System inkrementell aus unabhängigen, parallel arbeitenden Modulen aufgebaut werden, die nach und nach die Funktionalität erweitern. Dabei gibt es keine zentrale Datenbank für die Verhaltensstrategien. Jedes Modul kann im Prinzip selbst mit jedem anderen Modul und mit der Umwelt durch Wahrnehmen und Handel in Verbindung stehen. Es werden keine zentralen und peripheren Schichten unterschieden.
Will man intelligente Systeme bauen, ist man oft dazu verleitet, menschliche
Intelligenz zu kopieren. Dabei stellt sich die Frage, wie das Phänomen
menschliche Intelligenz in Teile zerlegt werden kann. Möglicherweise
ist es erfolgversprechender, immer komplexer werdende Systeme zu entwickeln,
dabei die entstehende Funktionalität zu beobachten und die Entwicklungsrichtung
entsprechend zu beeinflussen.
Die Idee für DD basiert auf der reaktiven Verhaltenssteuerung und Eigenschaften dynamischer Systeme, insbesondere der Selbstorganisation. Eine Grundlage für DD ist die sich ständig ändernde Situation, in der sich der Roboter befindet. Dies macht eine Unterscheidung von verschiedenen Verhaltensmodi sinnvoll. Der Roboter reagiert je nach Situation auf ein bestimmtes Bild der Sensoren unterschiedlich im verschiedenen Modi. Im Verteidigungsmodus z.B. würde ein Fußballroboter anders handeln als im Angriffsmodus. Übergänge zwischen den Modi entsprechen Verzweigungen im dynamischen System. Ein Übergang ist nicht kontinuierlich. Entweder der Roboter verteidigt oder er greift an. Die Entscheidung über den Übergang zwischen zwei Modi wird dynamisch in Abhängigkeit von den Sensordaten, also von der Umwelt getroffen.
Die DD Architektur besteht aus Verhaltenselementen, die in Schichten angeordnet sind. Unten befinden sich die elementaren, oben die komplexeren Verhaltenselemente. Zugriff auf Sensordaten haben alle Schichten, die Aktoren werden aber nur von den unteren Schichten direkt gesteuert.
Elementare Verhaltenselemente bestehen aus zwei Untersystemen ("Dual Dynamics"). Das erste System, der Ausführungsteil, berechnet ausführbare Aktionen wie Trajektorien und die entsprechenden Motorsteuerungen, um die Aufgabe auszuführen. (Genauer gesagt eine Funktion von den Sensordaten in die einzelnen Variablen, die alle Freiheitsgrade des Roboters beschreiben.) Die Verhaltenselemente des Ausführungsteils sind auch elementar in dem Sinne, daß sie in allen Modi gleich verlaufen, z.B. das Ballschießen.
Das zweite Untersystem, der Aktivierungsteil, reguliert in einer Variable (mit Wert zwischen 0 und 1) den Aktivierungsgrad des Verhaltens. Z.B. würde ein Auffahrsensor den Wert für das Verhalten "Hindernis Umfahren" auf 1 setzen. Die Verhaltenselemente des Aktivierungsteils können aber je nach Modus unterschiedlich arbeiten. Falls ein höheres Verhalten wie z.B. "Angriff" aktiv wird, kann seine Aktivierungsvariable einen Moduswechsel veranlassen. "Hindernis Umfahren" berücksichtigt bei Berechnung seiner Aktivierungsvariable die Aktivierungsvariable des "Angriff" Verhaltens als Kontrollparameter und wird in diesem Fall beim Auffahren auf ein Hindernis nicht aktiv (der Ball soll ja nicht umfahren werden). Ein Moduswechsel wird im DD System nur durch die Aktivierungsvariablen repräsentiert, was allerdings der Übersichtlichkeit und Nachvollziehbarkeit schadet.
Höhere Schichten stellen immer die Kontrollparameter für die
unteren Schichten zur Verfügung und bringen dadurch ihr Verhalten
zur Ausführung. Damit sie dazu kommen, müssen die unteren Schichten
ihre Aktivierungsvariablen öfter updaten als die oberen. Elementare
Verhaltenselemente werden also nicht von höheren Schichten aufgerufen,
sondern es findet eine allgemeine Einflußname über die Kontrollparameter
statt. Untere Schichten arbeiten auch ohne die höheren weiter.
[Bredenfeld 2] Dual Dynamics Environment und Dual Dynamics Design Tool - GMD, Institute of Autonomous Intelligent Systems (AiS) - Ansgar Bredenfeld - http://borneo.gmd.de/BE/dddtool/index.html
[Braitenberg] V. Braitenberg - Künstliche Wesen, Vieweg&Sohn, 1986
[Brooks] Cambrian Intelligence - Rodney A. Brooks, MIT-Press, 1999 - http://www.ai.mit.edu/
[Christaller] Autonome intelligente Systeme - Sciencefiction trifft auf die Realität - Thomas Christaller - www.gmd.de/spiegel/GMD-Spiegel3-499/Spiegel3499.html, www.gmd.de/spiegel/GMD-Spiegel3-499/Christaller.pdf
[Jaeger] The Dual Dynamics Design Scheme for Behavior-based Robots: A Tutorial - Herbert Jaeger, GMD, 1995,
[Mallot] Sehen und die Verarbeitung visueller Informationen, Eine Einführung - H.A. Mallot, Vieweg, 2000
[Möller 1] Biomimetische Robotik - Ralf Möller - http://www.ifi.unizh.ch/~moeller/biorobotics.html
[Möller 2] Insect Strategies of Visual Homing in Mobile Robots - Ralf Möller, Dimitrios Lambrinos, Thorsten Roggendorf, Rolf Pfeifer, Rüdiger Wehner - http://www.ifi.unizh.ch/~moeller/, http://www.ifi.unizh.ch/groups/ailab/people/moeller/documents/AAAI98.ps.gz
[Möller 3] Insect visual homing strategies in a robot with analog processing - Ralf Möller, 2000 - http://www.ifi.unizh.ch/~moeller/, http://www.ifi.unizh.ch/groups/ailab/people/moeller/documents/analog_robot.ps.gz
[Spenneberg] PDL Programming
Manual, Draft Version - Dirk Spenneberg, Eckart Schlottmann, Timo Höpfner,
Thomas Christaller, 1997 - www.gmd.de/FIT/KI/CogRob/Publications/CogRob.Publications.html

